[Click here for a PDF of this post with nicer formatting]
Reading.
Still covering chapter 1 material from the text [1].
Covering Professor Poppitz’s lecture notes: nonrelativistic limit of boosts (33); number of parameters of Lorentz transformations (34-35); introducing four-vectors, the metric tensor, the invariant “dot-product and SO(1,3) (36-40); the Poincare group (41); the convenience of “upper” and “lower” indices (42-43); tensors (44)
The Special Orthogonal group (for Euclidean space).
Lorentz transformations are like “rotations” for  that preserve
that preserve  . There are 6 continuous parameters:
. There are 6 continuous parameters:
\begin{itemize}
\item 3 rotations in  space
space
\item 3 “boosts” in  or
or 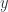 or
or  .
.
\end{itemize}
For rotations of space we talk about a group of transformations of 3D Euclidean space, and call this the  group. Here
group. Here 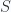 is for Special,
is for Special,  for Orthogonal, and
for Orthogonal, and  for the dimensions.
for the dimensions.
For a transformed vector in 3D space we write

Here is an orthogonal  matrix, and has the property
matrix, and has the property

Taking determinants, we have

and since  , we have
, we have

so our determinant must be

We work with the positive case only, avoiding the transformations that include reflections.
The Unitary condition  is an indication that the inner product is preserved. Observe that in matrix form we can write the inner product
is an indication that the inner product is preserved. Observe that in matrix form we can write the inner product

For a transformed vector  , we have
, we have  , and
, and

The Special Orthogonal group (for spacetime).
This generalizes to Lorentz boosts! There are two differences
\begin{enumerate}
\item Lorentz transforms should be  not and act in
not and act in  , and NOT
, and NOT  .
.
\item They should leave invariant NOT  , but
, but  .
.
\end{enumerate}
Don’t get confused that I demanded  rather than
rather than  . Expansion of this (squared) interval, provides just this four vector dot product and its invariance condition
. Expansion of this (squared) interval, provides just this four vector dot product and its invariance condition

Observe that we have the sum of two invariants plus our new cross term, so this cross term, (-2 times our dot product to be defined), must also be an invariant.
Introduce the four vector

Or  .
.
We will also write

Our inner product is

Introduce the matrix

This is called the Minkowski spacetime metric.
Then

\paragraph{Einstein summation convention}. Whenever indexes are repeated that are assumed to be summed over.
We also write



Our inner product

Under Lorentz boosts, we have

where

(for x-direction boosts)

But  must be such that
must be such that  is invariant. i.e.
is invariant. i.e.

This implies

Such ‘s are called “pseudo-orthogonal”.
Lorentz transformations are represented by the set of all pseudo-orthogonal matrices.
In symbols

Just as before we can take the determinant of both sides. Doing so we have

The  terms cancel, and since
terms cancel, and since  , this leaves us with
, this leaves us with  , or
, or

We take the  case only, so that the transformations do not change orientation (no reflection in space or time). This set of transformation forms the group
case only, so that the transformations do not change orientation (no reflection in space or time). This set of transformation forms the group

Special orthogonal, one time, 3 space dimensions.
Einstein relativity can be defined as the “laws of physics that leave four vectors invariant in the

symmetry group.
Here  is the group of translations in spacetime with 4 continuous parameters. The complete group of transformations that form the group of relativistic physics has
is the group of translations in spacetime with 4 continuous parameters. The complete group of transformations that form the group of relativistic physics has  continuous parameters.
continuous parameters.
This group is called the Poincare group of symmetry transforms.
More notation
Our inner product is written

but this is very cumbersome. The convenient way to write this is instead

where

Note: A check that we should always be able to make. Indexes that are not summed over should be conserved. So in the above we have a free  on the LHS, and should have a non-summed index on the RHS too (also lower matching lower, or upper matching upper).
on the LHS, and should have a non-summed index on the RHS too (also lower matching lower, or upper matching upper).
Non-matched indexes are bad in the same sort of sense that an expression like

isn’t well defined (assuming a vector space  and not a multivector Clifford algebra that is;)
and not a multivector Clifford algebra that is;)
Example explicitly:

We would not have objects of the form

for example. This is not a Lorentz invariant quantity.
\paragraph{Lorentz scalar example:} 
\paragraph{Lorentz vector example:} 
This last is also called a rank-1 tensor.
Lorentz rank-2 tensors: ex: 
or other 2-index objects.
Why in the world would we ever want to consider two index objects. We aren’t just trying to be hard on ourselves. Recall from classical mechanics that we have a two index object, the inertial tensor.
In mechanics, for a rigid body we had the energy

The inertial tensor was this object

or for a continuous body

In electrostatics we have the quadrupole tensor, … and we have other such objects all over physics.
Note that the energy  of the body above cannot depend on the coordinate system in use. This is a general property of tensors. These are object that transform as products of vectors, as
of the body above cannot depend on the coordinate system in use. This is a general property of tensors. These are object that transform as products of vectors, as  does.
does.
We call a rank-2 3-tensor. rank-2 because there are two indexes, and 3 because the indexes range from  to .
to .
The point is that tensors have the property that the transformed tensors transform as

Another example: the completely antisymmetric rank 3, 3-tensor

Dynamics
In Newtonian dynamics we have

An equation of motion should be expressed in terms of vectors. This equation is written in a way that shows that the law of physics is independent of the choice of coordinates. We can do this in the context of tensor algebra as well. Ironically, this will require us to explicitly work with the coordinate representation, but this work will be augmented by the fact that we require our tensors to transform in specific ways.
In Newtonian mechanics we can look to symmetries and the invariance of the action with respect to those symmetries to express the equations of motion. Our symmetries in Newtonian mechanics leave the action invariant with respect to spatial translation and with respect to rotation.
We want to express relativistic dynamics in a similar way, and will have to express the action as a Lorentz scalar. We are going to impose the symmetries of the Poincare group to determine the relativistic laws of dynamics, and the next task will be to consider the possibilities for our relativistic action, and see what that action implies for dynamics in a relativistic context.
References
[1] L.D. Landau and E.M. Lifshits. The classical theory of fields. Butterworth-Heinemann, 1980.






















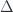





















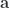 and
and  in that space. Utilizing a standard orthonormal basis
in that space. Utilizing a standard orthonormal basis 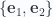 we can write
we can write
 , not yet knowing what we will end up with. That is
, not yet knowing what we will end up with. That is
 , so we have
, so we have
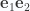 and
and  are in fact related, and we can see that by looking at the case of
are in fact related, and we can see that by looking at the case of  . For that we have
. For that we have









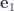 to
to  , can be expressed as
, can be expressed as
 and
and  are perpendicular unit vectors in that plane, then the rotation through angle
are perpendicular unit vectors in that plane, then the rotation through angle 

 that describes the plane and the orientation of the rotation (or by duality the direction of the normal in a 3D space). By avoiding a requirement to encode the rotation using a normal to the plane we have an method of expressing the rotation that works not only in 3D spaces, but also in 2D and greater than 3D spaces, something that isn’t possible when we restrict ourselves to traditional vector algebra (where quantities like the cross product can’t be defined in a 2D or 4D space, despite the fact that things they may represent, like torque are planar phenomena that do not have any intrinsic requirement for a normal that falls out of the plane.).
that describes the plane and the orientation of the rotation (or by duality the direction of the normal in a 3D space). By avoiding a requirement to encode the rotation using a normal to the plane we have an method of expressing the rotation that works not only in 3D spaces, but also in 2D and greater than 3D spaces, something that isn’t possible when we restrict ourselves to traditional vector algebra (where quantities like the cross product can’t be defined in a 2D or 4D space, despite the fact that things they may represent, like torque are planar phenomena that do not have any intrinsic requirement for a normal that falls out of the plane.).

 of magnitude
of magnitude  has the form
has the form


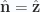 and
and  . Let’s derive this in the general case too.
. Let’s derive this in the general case too.
 (infinitesimal or otherwise) is then
(infinitesimal or otherwise) is then
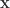 into components in the plane and in the direction of the normal
into components in the plane and in the direction of the normal 

 and
and  . Making the angle infinitesimal
. Making the angle infinitesimal  we have
we have


 basis which gives us
basis which gives us
 , and we get our desired result using plain old fashioned matrix algebra as well.
, and we get our desired result using plain old fashioned matrix algebra as well.
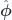 by geometrical intuition since it the plane unit vector at angle
by geometrical intuition since it the plane unit vector at angle  . That is
. That is
 by utilizing the right handedness of the coordinates since
by utilizing the right handedness of the coordinates since


 for the unit bivector in the
for the unit bivector in the 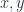 plane, we rotate
plane, we rotate
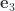 and
and  by
by  , our vectors in the plane rotate as
, our vectors in the plane rotate as
 since
since  ).
).


 we can write these in a compact exponential form.
we can write these in a compact exponential form.






 is a vector and has a nicely compact form, we need to decompose this into components in the
is a vector and has a nicely compact form, we need to decompose this into components in the 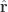 ,
, 








 to this and take differences
to this and take differences
 we have
we have
 , we find
, we find

![U[M]](https://s0.wp.com/latex.php?latex=U%5BM%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002) as in figure (\ref{fig:qmTwoL19:qmTwoL19fig1})
as in figure (\ref{fig:qmTwoL19:qmTwoL19fig1}) }
}

![\begin{aligned}{\left\langle {\psi} \right\rvert} U^\dagger[M] R_i U[M] {\left\lvert {\psi} \right\rangle}&= \tilde{r}_i = \sum_j M_{ij} \bar{r}_j \\ &={\left\langle {\psi} \right\rvert} \Bigl( U^\dagger[M] R_i U[M] \Bigr) {\left\lvert {\psi} \right\rangle}\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%7B%5Cleft%5Clangle+%7B%5Cpsi%7D+%5Cright%5Crvert%7D+U%5E%5Cdagger%5BM%5D+R_i+U%5BM%5D+%7B%5Cleft%5Clvert+%7B%5Cpsi%7D+%5Cright%5Crangle%7D%26%3D+%5Ctilde%7Br%7D_i+%3D+%5Csum_j+M_%7Bij%7D+%5Cbar%7Br%7D_j+%5C%5C+%26%3D%7B%5Cleft%5Clangle+%7B%5Cpsi%7D+%5Cright%5Crvert%7D+%5CBigl%28+U%5E%5Cdagger%5BM%5D+R_i+U%5BM%5D+%5CBigr%29+%7B%5Cleft%5Clvert+%7B%5Cpsi%7D+%5Cright%5Crangle%7D%5Cend%7Baligned%7D+&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![\begin{aligned}U^\dagger[M] R_i U[M] = \sum_j M_{ij} R_j\end{aligned} \hspace{\stretch{1}}(2.3)](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7DU%5E%5Cdagger%5BM%5D+R_i+U%5BM%5D+%3D+%5Csum_j+M_%7Bij%7D+R_j%5Cend%7Baligned%7D+%5Chspace%7B%5Cstretch%7B1%7D%7D%282.3%29&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
 that transform according to
that transform according to![\begin{aligned}U^\dagger[M] V_i U[M] = \sum_j M_{ij} V_j\end{aligned} \hspace{\stretch{1}}(2.4)](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7DU%5E%5Cdagger%5BM%5D+V_i+U%5BM%5D+%3D+%5Csum_j+M_%7Bij%7D+V_j%5Cend%7Baligned%7D+%5Chspace%7B%5Cstretch%7B1%7D%7D%282.4%29&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![\begin{aligned}\left[{V_i},{J_j}\right] = i \hbar \sum_k \epsilon_{ijk} V_k\end{aligned} \hspace{\stretch{1}}(2.5)](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Cleft%5B%7BV_i%7D%2C%7BJ_j%7D%5Cright%5D+%3D+i+%5Chbar+%5Csum_k+%5Cepsilon_%7Bijk%7D+V_k%5Cend%7Baligned%7D+%5Chspace%7B%5Cstretch%7B1%7D%7D%282.5%29&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
 we recover the familiar commutator rules for angular momentum, but this also holds for operators
we recover the familiar commutator rules for angular momentum, but this also holds for operators  ,
,  ,
,  , …
, …![\begin{aligned}U^\dagger[M] = U[M^{-1}] = U[M^\text{T}],\end{aligned} \hspace{\stretch{1}}(2.6)](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7DU%5E%5Cdagger%5BM%5D+%3D+U%5BM%5E%7B-1%7D%5D+%3D+U%5BM%5E%5Ctext%7BT%7D%5D%2C%5Cend%7Baligned%7D+%5Chspace%7B%5Cstretch%7B1%7D%7D%282.6%29&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![\begin{aligned}U^\dagger[M] V_i U^\dagger[M] = U^\dagger[M^\dagger] V_i U[M^\dagger] = \sum_j M_{ji} V_j\end{aligned} \hspace{\stretch{1}}(2.7)](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7DU%5E%5Cdagger%5BM%5D+V_i+U%5E%5Cdagger%5BM%5D+%3D+U%5E%5Cdagger%5BM%5E%5Cdagger%5D+V_i+U%5BM%5E%5Cdagger%5D+%3D+%5Csum_j+M_%7Bji%7D+V_j%5Cend%7Baligned%7D+%5Chspace%7B%5Cstretch%7B1%7D%7D%282.7%29&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![\begin{aligned}{\left\langle {\psi} \right\rvert} V_i {\left\lvert {\psi} \right\rangle}={\left\langle {\psi} \right\rvert}U^\dagger[M] \Bigl( U[M] V_i U^\dagger[M] \Bigr) U[M]{\left\lvert {\psi} \right\rangle}\end{aligned} \hspace{\stretch{1}}(2.8)](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%7B%5Cleft%5Clangle+%7B%5Cpsi%7D+%5Cright%5Crvert%7D+V_i+%7B%5Cleft%5Clvert+%7B%5Cpsi%7D+%5Cright%5Crangle%7D%3D%7B%5Cleft%5Clangle+%7B%5Cpsi%7D+%5Cright%5Crvert%7DU%5E%5Cdagger%5BM%5D+%5CBigl%28+U%5BM%5D+V_i+U%5E%5Cdagger%5BM%5D+%5CBigr%29+U%5BM%5D%7B%5Cleft%5Clvert+%7B%5Cpsi%7D+%5Cright%5Crangle%7D%5Cend%7Baligned%7D+%5Chspace%7B%5Cstretch%7B1%7D%7D%282.8%29&bg=fafcff&fg=2a2a2a&s=0&c=20201002)

![\begin{aligned}U[M] \tau_{ij} U^\dagger[M] = \sum_{lm} M_{li} M_{mj} \tau_{lm}\end{aligned} \hspace{\stretch{1}}(2.10)](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7DU%5BM%5D+%5Ctau_%7Bij%7D+U%5E%5Cdagger%5BM%5D+%3D+%5Csum_%7Blm%7D+M_%7Bli%7D+M_%7Bmj%7D+%5Ctau_%7Blm%7D%5Cend%7Baligned%7D+%5Chspace%7B%5Cstretch%7B1%7D%7D%282.10%29&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![\begin{aligned}U[M] S U^\dagger[M] = S\end{aligned} \hspace{\stretch{1}}(2.11)](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7DU%5BM%5D+S+U%5E%5Cdagger%5BM%5D+%3D+S%5Cend%7Baligned%7D+%5Chspace%7B%5Cstretch%7B1%7D%7D%282.11%29&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![\begin{aligned}\sum_i \tau_{ii}&=\sum_iU[M] \tau_{ii} U^\dagger[M] \\ &= \sum_i\sum_{lm} M_{li} M_{mi} \tau_{lm} \\ &= \sum_i\sum_{lm} M_{li} M_{im}^\text{T} \tau_{lm} \\ &= \sum_{lm} \delta_{lm} \tau_{lm} \\ &= \sum_{l} \tau_{ll} \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Csum_i+%5Ctau_%7Bii%7D%26%3D%5Csum_iU%5BM%5D+%5Ctau_%7Bii%7D+U%5E%5Cdagger%5BM%5D++%5C%5C+%26%3D+%5Csum_i%5Csum_%7Blm%7D+M_%7Bli%7D+M_%7Bmi%7D+%5Ctau_%7Blm%7D+%5C%5C+%26%3D+%5Csum_i%5Csum_%7Blm%7D+M_%7Bli%7D+M_%7Bim%7D%5E%5Ctext%7BT%7D+%5Ctau_%7Blm%7D+%5C%5C+%26%3D+%5Csum_%7Blm%7D+%5Cdelta_%7Blm%7D+%5Ctau_%7Blm%7D+%5C%5C+%26%3D+%5Csum_%7Bl%7D+%5Ctau_%7Bll%7D+%5Cend%7Baligned%7D+&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![\begin{aligned}U[M] {\left\lvert {j m''} \right\rangle} \end{aligned} \hspace{\stretch{1}}(2.12)](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7DU%5BM%5D+%7B%5Cleft%5Clvert+%7Bj+m%27%27%7D+%5Cright%5Crangle%7D+%5Cend%7Baligned%7D+%5Chspace%7B%5Cstretch%7B1%7D%7D%282.12%29&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
 .
.![\begin{aligned}U[M] {\left\lvert {j m''} \right\rangle} &=\sum_{m'} {\left\lvert {j m'} \right\rangle} {\left\langle {j m'} \right\rvert} U[M] {\left\lvert {j m''} \right\rangle} \\ &=\sum_{m'} {\left\lvert {j m'} \right\rangle} D^{(j)}_{m' m''}[M] \\ \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7DU%5BM%5D+%7B%5Cleft%5Clvert+%7Bj+m%27%27%7D+%5Cright%5Crangle%7D+%26%3D%5Csum_%7Bm%27%7D+%7B%5Cleft%5Clvert+%7Bj+m%27%7D+%5Cright%5Crangle%7D+%7B%5Cleft%5Clangle+%7Bj+m%27%7D+%5Cright%5Crvert%7D+U%5BM%5D+%7B%5Cleft%5Clvert+%7Bj+m%27%27%7D+%5Cright%5Crangle%7D++%5C%5C+%26%3D%5Csum_%7Bm%27%7D+%7B%5Cleft%5Clvert+%7Bj+m%27%7D+%5Cright%5Crangle%7D+D%5E%7B%28j%29%7D_%7Bm%27+m%27%27%7D%5BM%5D+%5C%5C+%5Cend%7Baligned%7D+&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![D^{(j)}_{m' m''}[M]](https://s0.wp.com/latex.php?latex=D%5E%7B%28j%29%7D_%7Bm%27+m%27%27%7D%5BM%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002) form a representation of the rotation group. These are in fact (not proved here) an irreducible representation.
form a representation of the rotation group. These are in fact (not proved here) an irreducible representation.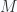 is chosen. There is some
is chosen. There is some  .
.

![\begin{aligned}U[M] {\left\lvert {\psi} \right\rangle} = &= \sum_{m'} U[M] {\left\lvert {j m'} \right\rangle} \left\langle{{j m'}} \vert {{\psi}}\right\rangle \\ &= \sum_{m'} U[M] {\left\lvert {j m'} \right\rangle} \bar{a}_{m'} \\ &= \sum_{m', m''} {\left\lvert {j m''} \right\rangle} {\left\langle {j m''} \right\rvert}U[M] {\left\lvert {j m'} \right\rangle} \bar{a}_{m'} \\ &= \sum_{m', m''} {\left\lvert {j m''} \right\rangle} D^{(j)}_{m'', m'}\bar{a}_{m'} \\ &= \sum_{m''} \tilde{a}_{m''} {\left\lvert {j m''} \right\rangle} \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7DU%5BM%5D+%7B%5Cleft%5Clvert+%7B%5Cpsi%7D+%5Cright%5Crangle%7D+%3D+%26%3D+%5Csum_%7Bm%27%7D+U%5BM%5D+%7B%5Cleft%5Clvert+%7Bj+m%27%7D+%5Cright%5Crangle%7D+%5Cleft%5Clangle%7B%7Bj+m%27%7D%7D+%5Cvert+%7B%7B%5Cpsi%7D%7D%5Cright%5Crangle+%5C%5C+%26%3D+%5Csum_%7Bm%27%7D+U%5BM%5D+%7B%5Cleft%5Clvert+%7Bj+m%27%7D+%5Cright%5Crangle%7D+%5Cbar%7Ba%7D_%7Bm%27%7D+%5C%5C+%26%3D+%5Csum_%7Bm%27%2C+m%27%27%7D+%7B%5Cleft%5Clvert+%7Bj+m%27%27%7D+%5Cright%5Crangle%7D+%7B%5Cleft%5Clangle+%7Bj+m%27%27%7D+%5Cright%5Crvert%7DU%5BM%5D+%7B%5Cleft%5Clvert+%7Bj+m%27%7D+%5Cright%5Crangle%7D+%5Cbar%7Ba%7D_%7Bm%27%7D+%5C%5C+%26%3D+%5Csum_%7Bm%27%2C+m%27%27%7D+%7B%5Cleft%5Clvert+%7Bj+m%27%27%7D+%5Cright%5Crangle%7D+D%5E%7B%28j%29%7D_%7Bm%27%27%2C+m%27%7D%5Cbar%7Ba%7D_%7Bm%27%7D+%5C%5C+%26%3D+%5Csum_%7Bm%27%27%7D+%5Ctilde%7Ba%7D_%7Bm%27%27%7D+%7B%5Cleft%5Clvert+%7Bj+m%27%27%7D+%5Cright%5Crangle%7D+%5Cend%7Baligned%7D+&bg=fafcff&fg=2a2a2a&s=0&c=20201002)


 operators
operators  ,
,  as the elements of a spherical tensor of rank
as the elements of a spherical tensor of rank  if
if ![\begin{aligned}U[M] {T_k}^q U^\dagger[M] = \sum_{q'} D^{(j)}_{q' q} {T_k}^{q'}\end{aligned} \hspace{\stretch{1}}(2.16)](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7DU%5BM%5D+%7BT_k%7D%5Eq+U%5E%5Cdagger%5BM%5D+%3D+%5Csum_%7Bq%27%7D+D%5E%7B%28j%29%7D_%7Bq%27+q%7D+%7BT_k%7D%5E%7Bq%27%7D%5Cend%7Baligned%7D+%5Chspace%7B%5Cstretch%7B1%7D%7D%282.16%29&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
 is a ket for a single particle. Perhaps we are talking about an electron without spin, and write
is a ket for a single particle. Perhaps we are talking about an electron without spin, and write
 and after dropping
and after dropping  . So
. So![\begin{aligned}{\left\langle {\mathbf{r}} \right\rvert} U[M] {\left\lvert {\psi} \right\rangle} =\sum_{m''} \sum_{m'} D^{(j)}_{m'' m} \bar{a}_{m'} Y_{l m''}(\theta, \phi) \end{aligned} \hspace{\stretch{1}}(2.17)](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%7B%5Cleft%5Clangle+%7B%5Cmathbf%7Br%7D%7D+%5Cright%5Crvert%7D+U%5BM%5D+%7B%5Cleft%5Clvert+%7B%5Cpsi%7D+%5Cright%5Crangle%7D+%3D%5Csum_%7Bm%27%27%7D+%5Csum_%7Bm%27%7D+D%5E%7B%28j%29%7D_%7Bm%27%27+m%7D+%5Cbar%7Ba%7D_%7Bm%27%7D+Y_%7Bl+m%27%27%7D%28%5Ctheta%2C+%5Cphi%29+%5Cend%7Baligned%7D+%5Chspace%7B%5Cstretch%7B1%7D%7D%282.17%29&bg=fafcff&fg=2a2a2a&s=0&c=20201002)

![\begin{aligned}{\left\langle {\mathbf{r}} \right\rvert} U[M] {\left\lvert {\psi} \right\rangle} &=\sum_{m''} Y_{l m''}(\theta, \phi) D^{(j)}_{m'' m} \\ &=Y_{l m}(\theta, \phi) \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%7B%5Cleft%5Clangle+%7B%5Cmathbf%7Br%7D%7D+%5Cright%5Crvert%7D+U%5BM%5D+%7B%5Cleft%5Clvert+%7B%5Cpsi%7D+%5Cright%5Crangle%7D+%26%3D%5Csum_%7Bm%27%27%7D+Y_%7Bl+m%27%27%7D%28%5Ctheta%2C+%5Cphi%29+D%5E%7B%28j%29%7D_%7Bm%27%27+m%7D+%5C%5C+%26%3DY_%7Bl+m%7D%28%5Ctheta%2C+%5Cphi%29+%5Cend%7Baligned%7D+&bg=fafcff&fg=2a2a2a&s=0&c=20201002)



![\begin{aligned}U[M] Y_{lm}(X, Y, Z) U^\dagger[M] =\sum_{m''} Y_{l m''}(X, Y, Z)D^{(j)}_{m'' m} \end{aligned} \hspace{\stretch{1}}(2.21)](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7DU%5BM%5D+Y_%7Blm%7D%28X%2C+Y%2C+Z%29+U%5E%5Cdagger%5BM%5D+%3D%5Csum_%7Bm%27%27%7D+Y_%7Bl+m%27%27%7D%28X%2C+Y%2C+Z%29D%5E%7B%28j%29%7D_%7Bm%27%27+m%7D+%5Cend%7Baligned%7D+%5Chspace%7B%5Cstretch%7B1%7D%7D%282.21%29&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
 .
.  through an angle
through an angle  .
. and
and 
 like vectors and write
like vectors and write

 a unitary operator?}
a unitary operator?} is unitary if
is unitary if  , where
, where  is the identity operator. We take Hermitian conjugates, which in this case is just the transpose since all elements of the matrix are real, and multiply
is the identity operator. We take Hermitian conjugates, which in this case is just the transpose since all elements of the matrix are real, and multiply
 and write
and write  . These are related as
. These are related as
 and write
and write 






 , an arbitrary function. Take
, an arbitrary function. Take  is very small so that
is very small so that













 is spin component one. For
is spin component one. For  this would be
this would be  .
.




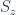 operation acting on the vector parts, and the
operation acting on the vector parts, and the  operator acting on the functional dependence.
operator acting on the functional dependence.
 plane
plane







 , so our gradient in spherical coordinates is
, so our gradient in spherical coordinates is





 and
and 

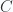 is Hermitian. This is a powerful result hiding away in this problem. I haven’t actually managed to prove this yet to my satisfaction, but working through some examples is highly worthwhile. In particular it is interesting to compute the matrix
is Hermitian. This is a powerful result hiding away in this problem. I haven’t actually managed to prove this yet to my satisfaction, but working through some examples is highly worthwhile. In particular it is interesting to compute the matrix 

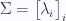




 , with eigenvectors proportional to
, with eigenvectors proportional to 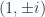 respectively. Our decomposition for
respectively. Our decomposition for 




 , this also provides us with a trigonometric expansion
, this also provides us with a trigonometric expansion
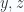 rotation, or a
rotation, or a 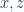 rotation. Those are, respectively
rotation. Those are, respectively
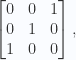
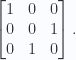

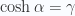 , and
, and  .
.



 is Hermitian.
is Hermitian.


 ,
,  ,
,  , and
, and  , we want to map
, we want to map
 , and
, and  . With
. With 






 element of the matrix product in the interior is
element of the matrix product in the interior is
 element of the matrix product in the interior is
element of the matrix product in the interior is


 , and
, and  , and get
, and get
 in polar form. Now, let’s do it the wrong way, dotting our gradient with itself.
in polar form. Now, let’s do it the wrong way, dotting our gradient with itself.

 derivatives are zero since these have no radial dependence, but we do have
derivatives are zero since these have no radial dependence, but we do have 

 , and
, and  , instead of using the obscure geometric algebra quaterionic rotation exponential operators.)
, instead of using the obscure geometric algebra quaterionic rotation exponential operators.)

{kind=link}