Understanding how to apply Stokes theorem to higher dimensional spaces, non-Euclidean metrics, and with curvilinear coordinates has been a long standing goal.
A traditional answer to these questions can be found in the formalism of differential forms, as covered for example in [2], and [8]. However, both of those texts, despite their small size, are intensely scary. I also found it counter intuitive to have to express all physical quantities as forms, since there are many times when we don’t have any pressing desire to integrate these.
Later I encountered Denker’s straight wire treatment [1], which states that the geometric algebra formulation of Stokes theorem has the form

This is simple enough looking, but there are some important details left out. In particular the grades do not match, so there must be some sort of implied projection or dot product operations too. We also need to understand how to express the hypervolume and hypersurfaces when evaluating these integrals, especially when we want to use curvilinear coordinates.
I’d attempted to puzzle through these details previously. A collection of these attempts, to be removed from my collection of geometric algebra notes, can be found in [4]. I’d recently reviewed all of these and wrote a compact synopsis [5] of all those notes, but in the process of doing so, I realized there was a couple of fundamental problems with the approach I had used.
One detail that was that I failed to understand, was that we have a requirement for treating a infinitesimal region in the proof, then summing over such regions to express the boundary integral. Understanding that the boundary integral form and its dot product are both evaluated only at the end points of the integral region is an important detail that follows from such an argument (as used in proof of Stokes theorem for a 3D Cartesian space in [7].)
I also realized that my previous attempts could only work for the special cases where the dimension of the integration volume also equaled the dimension of the vector space. The key to resolving this issue is the concept of the tangent space, and an understanding of how to express the projection of the gradient onto the tangent space. These concepts are covered thoroughly in [6], which also introduces Stokes theorem as a special case of a more fundamental theorem for integration of geometric algebraic objects. My objective, for now, is still just to understand the generalization of Stokes theorem, and will leave the fundamental theorem of geometric calculus to later.
Now that these details are understood, the purpose of these notes is to detail the Geometric algebra form of Stokes theorem, covering its generalization to higher dimensional spaces and non-Euclidean metrics (i.e. especially those used for special relativity and electromagnetism), and understanding how to properly deal with curvilinear coordinates. This generalization has the form
Theorem 1. Stokes’ Theorem
For blades 
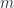
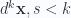

Here the volume integral is over a 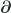

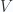
It takes some work to give this more concrete meaning. I will attempt to do so in a gradual fashion, and provide a number of examples that illustrate some of the relevant details.
Basic notation
A finite vector space, not necessarily Euclidean, with basis 


This is an Euclidean space when 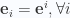
To select from a multivector 



The scalar portion of a multivector

The grade selection operators can be used to define the outer and inner products. For blades 




Written out explicitly for odd grade blades 

Similarly for even grade blades these are

It will be useful to employ the cyclic scalar reordering identity for the scalar selection operator

For an 


The pseudoscalar may commute or anticommute with other blades in the space. We may also form a pseudoscalar for a subspace spanned by vectors 

Curvilinear coordinates
For our purposes a manifold can be loosely defined as a parameterized surface. For example, a 2D manifold can be considered a surface in an 

Note that the indices here do not represent exponentiation. We can construct a basis for the manifold as

On the manifold we can calculate a reciprocal basis 

Associated implicitly with this basis is a curvilinear coordinate representation defined by the projection operation

(sums over mixed indices are implied). These coordinates can be calculated by taking dot products with the reciprocal frame vectors

In this document all coordinates are with respect to a specific curvilinear basis, and not with respect to the standard basis 
Similar to the usual notation for derivatives with respect to the standard basis coordinates we form a lower index partial derivative operator

so that when the complete vector space is spanned by 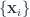

This can be motivated by noting that the directional derivative is defined by

When the basis

This is called the vector derivative.
See [6] for a more complete discussion of the gradient and vector derivatives in curvilinear coordinates.
Green’s theorem
Given a two parameter (


We assume that the vector space is of dimension two or greater but otherwise unrestricted, and need not have an Euclidean basis. Here 
Theorem 2. Green’s Theorem
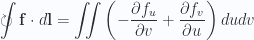
Following the arguments used in [7] for Stokes theorem in three dimensions, we first evaluate the loop integral along the differential element of the surface at the point 


Fig 1.1. Infinitesimal loop integral
Over the infinitesimal area, the loop integral decomposes into

where the differentials along the curve are

It is assumed that the parameterization change 

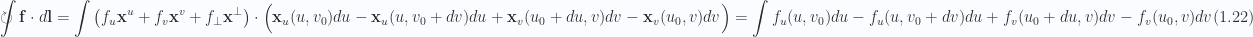
With the distances being infinitesimal, these differences can be rewritten as partial differentials
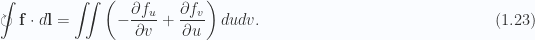
We can now sum over a larger area as in fig. 1.2

Fig 1.2. Sum of infinitesimal loops
All the opposing oriented loop elements cancel, so the integral around the complete boundary of the surface 
We will see that Green’s theorem is a special case of the Curl (Stokes) theorem. This observation will also provide a geometric interpretation of the right hand side area integral of thm. 2, and allow for a coordinate free representation.
Special case:
An important special case of Green’s theorem is for a Euclidean two dimensional space where the vector function is

Here Green’s theorem takes the form

Curl theorem, two volume vector field
Having examined the right hand side of thm. 1 for the very simplest geometric object
First we need to assign a meaning to 

that area element is

This is the oriented area element that lies in the tangent plane at the point of evaluation, and has the magnitude of the area of that segment of the surface, as depicted in fig. 1.3.

Fig 1.3. Oriented area element tiling of a surface
Observe that we have no requirement to introduce a normal to the surface to describe the direction of the plane. The wedge product provides the information about the orientation of the place in the space, even when the vector space that our vector lies in has dimension greater than three.
Proceeding with the expansion of the dot product of the area element with the curl, using eq. 1.0.6, eq. 1.0.7, and eq. 1.0.8, and a scalar selection operation, we have

Let’s proceed to expand the inner dot product

The complete curl term is thus
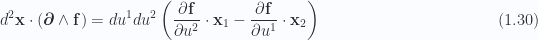
This almost has the form of eq. 1.23, although that is not immediately obvious. Working backwards, using the shorthand 

This relates the two parameter surface integral of the curl to the loop integral over its boundary

This is the very simplest special case of Stokes theorem. When written in the general form of Stokes thm. 1
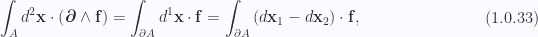
we must remember (the 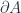

Expanded out in full this is

which can be cross checked against fig. 1.4 to demonstrate that this specifies a clockwise orientation. For the surface with oriented area 

Fig 1.4. Clockwise loop
Example: Green’s theorem, a 2D Cartesian parameterization for a Euclidean space
For a Cartesian 2D Euclidean parameterization of a vector field and the integration space, Stokes theorem should be equivalent to Green’s theorem eq. 1.0.25. Let’s expand both sides of eq. 1.0.32 independently to verify equality. The parameterization is

Here the dual basis is the basis, and the projection onto the tangent space is just the gradient

The volume element is an area weighted pseudoscalar for the space

and the curl of a vector 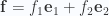

So, the LHS of Stokes theorem takes the coordinate form
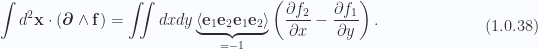
For the RHS, following fig. 1.5, we have
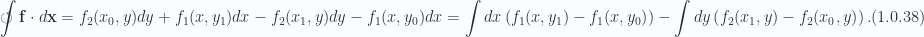
As expected, we can also obtain this by integrating eq. 1.0.38.

Fig 1.5. Euclidean 2D loop
Example: Cylindrical parameterization
Let’s now consider a cylindrical parameterization of a 4D space with Euclidean metric 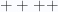

With 


Fig 1.6. Cylindrical polar parameterization
Note that the Euclidean case where 
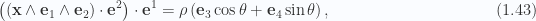
whereas for the Minkowski case where 
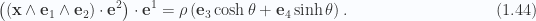
Within such a space consider the surface along 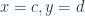

The tangent space unit vectors are

and

Observe that both of these vectors have their origin at the point of evaluation, and aren’t relative to the absolute origin used to parameterize the complete space.
We wish to compute the volume element for the tangent plane. Noting that 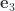


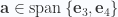

so

The tangent space volume element is thus

With the tangent plane vectors both perpendicular we don’t need the general lemma 6 to compute the reciprocal basis, but can do so by inspection

and

Observe that the latter depends on the metric signature.
The vector derivative, the projection of the gradient on the tangent space, is

From this we see that acting with the vector derivative on a scalar radial only dependent function 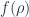

Expanding the curl in coordinates is messier, but yields in the end when tackled with sufficient care
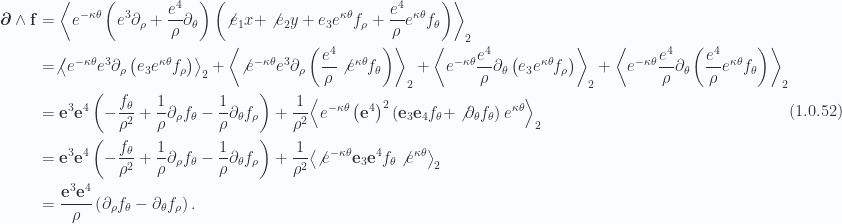
After all this reduction, we can now state in coordinates the LHS of Stokes theorem explicitly
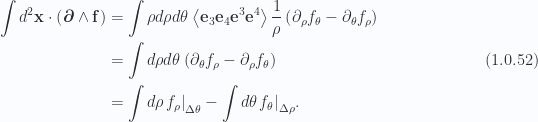
Now compare this to the direct evaluation of the loop integral portion of Stokes theorem. Expressing this using eq. 1.0.34, we have the same result

This example highlights some of the power of Stokes theorem, since the reduction of the volume element differential form was seen to be quite a chore (and easy to make mistakes doing.)
Example: Composition of boost and rotation
Working in a 
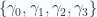



where 
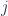
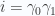

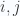

and

Let’s calculate the tangent space vectors for this parameterization, assuming that the particle is at an initial spacetime position of 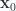

To calculate the tangent space vectors for this subspace we note that

and

The tangent space vectors are therefore

Continuing a specific example where 
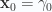


and

By inspection the dual basis for this parameterization is

So, Stokes theorem, applied to a spacetime vector

Since the point is to avoid the curl integral, we did not actually have to state it explicitly, nor was there any actual need to calculate the dual basis.
Example: Dual representation in three dimensions
It’s clear that there is a projective nature to the differential form 
When we parameterize a normal direction to the tangent space, so that for a 2D tangent space spanned by curvilinear coordinates 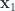
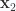


and express the orientation of the tangent space area element in terms of a pseudoscalar that includes this normal direction

Inserting this into an expansion of the curl form we have
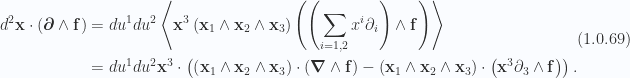
Observe that this last term, the contribution of the component of the gradient perpendicular to the tangent space, has no 
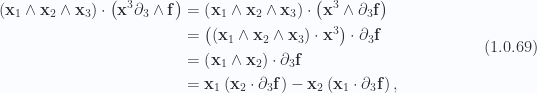
leaving
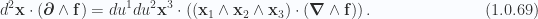
Now scale the normal vector and its dual to have unit norm as follows

so that for 

This scaling choice is illustrated in fig. 1.7, and represents the “outwards” normal. With such a scaling choice we have

Fig 1.7. Outwards normal

and almost have the desired cross product representation

With the duality identity 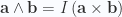

Note that the orientation of the loop integral in the traditional statement of the 3D Stokes theorem is counterclockwise instead of clockwise, as written here.
Stokes theorem, three variable volume element parameterization
We can restate the identity of thm. 1 in an equivalent dot product form.

Here 
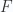
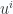
We’ve seen one specific example of this above in the expansions of eq. 1.28, and eq. 1.29, however, the equivalent result of eq. 1.0.78, somewhat magically, applies to any degree blade and volume element provided the degree of the blade is less than that of the volume element (i.e. 
As an expositional example, consider a three variable volume element parameterization, and a vector blade

It should not be surprising that this has the structure found in the theory of differential forms. Using the differentials for each of the parameterization “directions”, we can write this dot product expansion as

Observe that the sign changes with each element of 
Digression
As was the case with the loop integral, we expect that the coordinate representation has a representation that can be expressed as a number of antisymmetric terms. A bit of experimentation shows that such a sum, after dropping the parameter space volume element factor, is
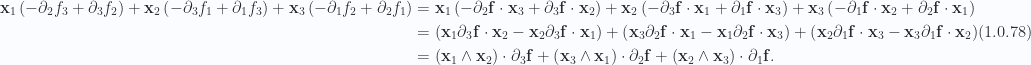
To proceed with the integration, we must again consider an infinitesimal volume element, for which the partial can be evaluated as the difference of the endpoints, with all else held constant. For this three variable parameterization, say, 
![[u_0,u_0 + du]](https://s0.wp.com/latex.php?latex=%5Bu_0%2Cu_0+%2B+du%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![[v_0,v_0 + dv]](https://s0.wp.com/latex.php?latex=%5Bv_0%2Cv_0+%2B+dv%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![[w_0,w_0 + dw]](https://s0.wp.com/latex.php?latex=%5Bw_0%2Cw_0+%2B+dw%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002)

Extending this over the ranges ![[u_0,u_0 + \Delta u]](https://s0.wp.com/latex.php?latex=%5Bu_0%2Cu_0+%2B+%5CDelta+u%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![[v_0,v_0 + \Delta v]](https://s0.wp.com/latex.php?latex=%5Bv_0%2Cv_0+%2B+%5CDelta+v%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![[w_0,w_0 + \Delta w]](https://s0.wp.com/latex.php?latex=%5Bw_0%2Cw_0+%2B+%5CDelta+w%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002)

where the evaluation of the dot products with
Example: Euclidean spherical polar parameterization of 3D subspace
Consider an Euclidean space where a 3D subspace is parameterized using spherical coordinates, as in

The tangent space basis for the subspace situated at some fixed 

While we can use the general relation of lemma 7 to compute the reciprocal basis. That is

However, a naive attempt at applying this without algebraic software is a route that requires a lot of care, and is easy to make mistakes doing. In this case it is really not necessary since the tangent space basis only requires scaling to orthonormalize, satisfying for

This allows us to read off the dual basis for the tangent volume by inspection

Should we wish to explicitly calculate the curl on the tangent space, we would need these. The area and volume elements are also messy to calculate manually. This expansion can be found in the Mathematica notebook \nbref{sphericalSurfaceAndVolumeElements.nb}, and is
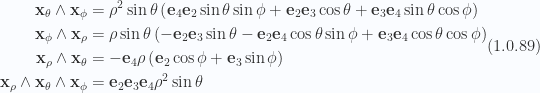
Those area elements have a Geometric algebra factorization that are perhaps useful
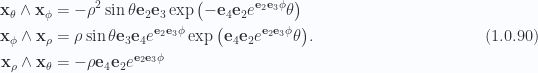
One of the beauties of Stokes theorem is that we don’t actually have to calculate the dual basis on the tangent space to proceed with the integration. For that calculation above, where we had a normal tangent basis, I still used software was used as an aid, so it is clear that this can generally get pretty messy.
To apply Stokes theorem to a vector field we can use eq. 1.0.82 to write down the integral directly

Observe that eq. 1.0.90 is a vector valued integral that expands to
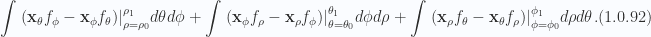
This could easily be a difficult integral to evaluate since the vectors 
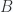

There is a geometric interpretation to these oriented area integrals, especially when written out explicitly in terms of the differentials along the parameterization directions. Pulling out a sign explicitly to match the geometry (as we had to also do for the line integrals in the two parameter volume element case), we can write this as
When written out in this differential form, each of the respective area elements is an oriented area along one of the faces of the parameterization volume, much like the line integral that results from a two parameter volume curl integral. This is visualized in fig. 1.8. In this figure, faces (1) and (3) are “top faces”, those with signs matching the tops of the evaluation ranges eq. 1.0.94, whereas face (2) is a bottom face with a sign that is correspondingly reversed.

Fig 1.8. Boundary faces of a spherical parameterization region
Example: Minkowski hyperbolic-spherical polar parameterization of 3D subspace
Working with a three parameter volume element in a Minkowski space does not change much. For example in a 4D space with

This has tangent space basis elements

This is a normal basis, but again not orthonormal. Specifically, for 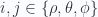

where we see that the radial vector 

The area elements are
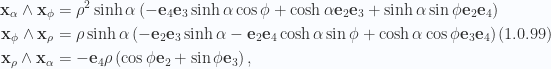
or
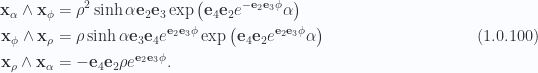
The volume element also reduces nicely, and is

The area and volume element reductions were once again messy, done in software using \nbref{sphericalSurfaceAndVolumeElementsMinkowski.nb}. However, we really only need eq. 1.0.96 to perform the Stokes integration.
Stokes theorem, four variable volume element parameterization
Volume elements for up to four parameters are likely of physical interest, with the four volume elements of interest for relativistic physics in 

We follow the same procedure to calculate the corresponding boundary surface “area” element (with dimensions of volume in this case). This is

Our boundary value surface element is therefore

where it is implied that this (and the dot products with
Duality and its relation to the pseudoscalar.
Looking to eq. 1.0.181 of lemma 6, and scaling the wedge product 
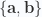

This allows us to express the unit vector in the direction of 

Following the pattern of eq. 1.0.181, it is clear how to express the dual vectors for higher dimensional subspaces. For example
or for the unit vector in the direction of
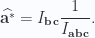
Divergence theorem.
When the curl integral is a scalar result we are able to apply duality relationships to obtain the divergence theorem for the corresponding space. We will be able to show that a relationship of the following form holds

Here 
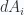
First note that, for a scalar Stokes integral we are integrating the vector derivative curl of a blade 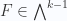

Multiplication of

Stokes theorem takes the form

or

where we will see that the vector 

The second last step uses lemma 8, and the last writes 
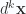

Let’s now return to the normal vector 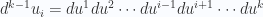


We’ve seen in eq. 1.0.106 and lemma 7 that the dual of vector 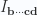


or

This allows us to write

where 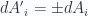
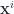

This leaves us with
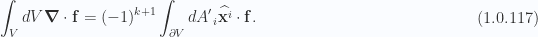
To spell out the details, we have to be very careful with the signs. However, that is a job best left for specific examples.
Example: 2D divergence theorem
Let’s start back at

On the left our integral can be rewritten as

where 

For the boundary form we have

The duality relations for the tangent space are

or

Back substitution into the line element gives

Writing (no sum) 

This provides us a divergence and normal relationship, with 

Let’s consider this graphically for an Euclidean metric as illustrated in fig. 1.9.

Fig 1.9. Normals on area element
We see that
- along
the outwards normal is
,
- along
the outwards normal is
,
- along
the outwards normal is
, and
- along
the outwards normal is
Writing that outwards normal as 

Note that we can use the same algebraic notion of outward normal for non-Euclidean spaces, although cannot expect the geometry to look anything like that of the figure.
Example: 3D divergence theorem
As with the 2D example, let’s start back with

In a 3D space, the pseudoscalar commutes with all grades, so we have
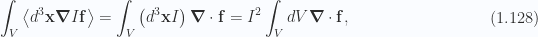
where 

In the boundary integral our dual two form is

where 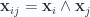

Observe that we can do a cyclic permutation of a 3 blade without any change of sign, for example

Because of this we can write the dual two form as we expressed the normals in lemma 7
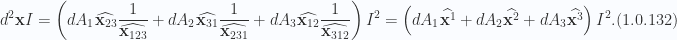
We can now state the 3D divergence theorem, canceling out the metric and orientation dependent term

where (sums implied)

and

The outwards normals at the upper integration ranges of a three parameter surface are depicted in fig. 1.10.

Fig 1.10. Outwards normals on volume at upper integration ranges.
This sign alternation originates with the two form elements 
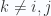
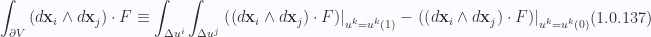
In the context of the divergence theorem, this means that we are implicitly requiring the dot products 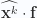

Example: 4D divergence theorem
Applying Stokes theorem to a trivector 

Here the pseudoscalar has been picked to have the same orientation as the hypervolume element 


Here, we’ve written

Observe that the dual representation nicely removes the alternation of sign that we had in the Stokes theorem boundary integral, since each alternation of the wedged vectors in the pseudoscalar changes the sign once.
As before, we define the outwards normals as 

so that the 4D divergence theorem looks just like the 2D and 3D cases

Here we define the volume scaled normal as

As before, we have made use of the implicit fact that the three form (and it’s dot product with
We also obtain explicit instructions from this formalism how to compute the “outwards” normal for this surface in a 4D space (unit scaling of the dual basis elements), something that we cannot compute using any sort of geometrical intuition. For free we’ve obtained a result that applies to both Euclidean and Minkowski (or other non-Euclidean) spaces.
Volume integral coordinate representations
It may be useful to formulate the curl integrals in tensor form. For vectors


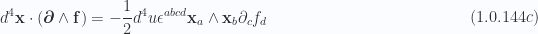


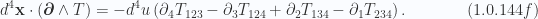
Here the bivector 


where


For the trivector components are also antisymmetric, changing sign with any interchange of indices.
Note that eq. 1.0.144d and eq. 1.0.144f appear much different on the surface, but both have the same structure. This can be seen by writing for former as

In both of these we have an alternation of sign, where the tensor index skips one of the volume element indices is sequence. We’ve seen in the 4D divergence theorem that this alternation of sign can be related to a duality transformation.
In integral form (no sum over indexes 

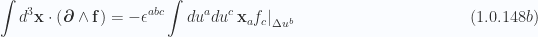



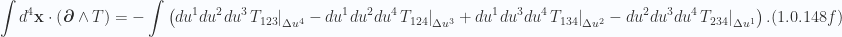
Of these, I suspect that only eq. 1.0.148a and eq. 1.0.148d are of use.
Final remarks
Because we have used curvilinear coordinates from the get go, we have arrived naturally at a formulation that works for both Euclidean and non-Euclidean geometries, and have demonstrated that Stokes (and the divergence theorem) holds regardless of the geometry or the parameterization. We also know explicitly how to formulate both theorems for any parameterization that we choose, something much more valuable than knowledge that this is possible.
For the divergence theorem we have introduced the concept of outwards normal (for example in 3D, eq. 1.0.136), which still holds for non-Euclidean geometries. We may not be able to form intuitive geometrical interpretations for these normals, but do have an algebraic description of them.
Appendix
Problems
Question: Expand volume elements in coordinates
Show that the coordinate representation for the volume element dotted with the curl can be represented as a sum of antisymmetric terms. That is
- (a)Prove eq. 1.0.144a
- (b)Prove eq. 1.0.144b
- (c)Prove eq. 1.0.144c
- (d)Prove eq. 1.0.144d
- (e)Prove eq. 1.0.144e
- (f)Prove eq. 1.0.144f
Answer
(a) Two parameter volume, curl of vector

(b) Three parameter volume, curl of vector

(c) Four parameter volume, curl of vector
![\begin{aligned}\begin{aligned}d^4 \mathbf{x} \cdot \left( { \boldsymbol{\partial} \wedge \mathbf{f} } \right)&=d^4 u\Bigl( { \left( { \mathbf{x}_1 \wedge \mathbf{x}_2 \wedge \mathbf{x}_3 \wedge \mathbf{x}_4 } \right) \cdot \mathbf{x}^i } \Bigr) \cdot \partial_i \mathbf{f} \\ &=d^4 u\Bigl( {\left( { \mathbf{x}_1 \wedge \mathbf{x}_2 \wedge \mathbf{x}_3 } \right) \cdot \partial_4 \mathbf{f}-\left( { \mathbf{x}_1 \wedge \mathbf{x}_2 \wedge \mathbf{x}_4 } \right) \cdot \partial_3 \mathbf{f}+\left( { \mathbf{x}_1 \wedge \mathbf{x}_3 \wedge \mathbf{x}_4 } \right) \cdot \partial_2 \mathbf{f}-\left( { \mathbf{x}_2 \wedge \mathbf{x}_3 \wedge \mathbf{x}_4 } \right) \cdot \partial_1 \mathbf{f}} \Bigr) \\ &=d^4 u\Bigl( { \\ &\quad\quad \left( { \mathbf{x}_1 \wedge \mathbf{x}_2 } \right) \mathbf{x}_3 \cdot \partial_4 \mathbf{f}-\left( { \mathbf{x}_1 \wedge \mathbf{x}_3 } \right) \mathbf{x}_2 \cdot \partial_4 \mathbf{f}+\left( { \mathbf{x}_2 \wedge \mathbf{x}_3 } \right) \mathbf{x}_1 \cdot \partial_4 \mathbf{f} \\ &\quad-\left( { \mathbf{x}_1 \wedge \mathbf{x}_2 } \right) \mathbf{x}_4 \cdot \partial_3 \mathbf{f}+\left( { \mathbf{x}_1 \wedge \mathbf{x}_4 } \right) \mathbf{x}_2 \cdot \partial_3 \mathbf{f}-\left( { \mathbf{x}_2 \wedge \mathbf{x}_4 } \right) \mathbf{x}_1 \cdot \partial_3 \mathbf{f} \\ &\quad+ \left( { \mathbf{x}_1 \wedge \mathbf{x}_3 } \right) \mathbf{x}_4 \cdot \partial_2 \mathbf{f}-\left( { \mathbf{x}_1 \wedge \mathbf{x}_4 } \right) \mathbf{x}_3 \cdot \partial_2 \mathbf{f}+\left( { \mathbf{x}_3 \wedge \mathbf{x}_4 } \right) \mathbf{x}_1 \cdot \partial_2 \mathbf{f} \\ &\quad-\left( { \mathbf{x}_2 \wedge \mathbf{x}_3 } \right) \mathbf{x}_4 \cdot \partial_1 \mathbf{f}+\left( { \mathbf{x}_2 \wedge \mathbf{x}_4 } \right) \mathbf{x}_3 \cdot \partial_1 \mathbf{f}-\left( { \mathbf{x}_3 \wedge \mathbf{x}_4 } \right) \mathbf{x}_2 \cdot \partial_1 \mathbf{f} \\ &\qquad} \Bigr) \\ &=d^4 u\Bigl( {\mathbf{x}_1 \wedge \mathbf{x}_2 \partial_{[4} f_{3]}+\mathbf{x}_1 \wedge \mathbf{x}_3 \partial_{[2} f_{4]}+\mathbf{x}_1 \wedge \mathbf{x}_4 \partial_{[3} f_{2]}+\mathbf{x}_2 \wedge \mathbf{x}_3 \partial_{[4} f_{1]}+\mathbf{x}_2 \wedge \mathbf{x}_4 \partial_{[1} f_{3]}+\mathbf{x}_3 \wedge \mathbf{x}_4 \partial_{[2} f_{1]}} \Bigr) \\ &=- \frac{1}{2} d^4 u \epsilon^{abcd} \mathbf{x}_a \wedge \mathbf{x}_b \partial_{c} f_{d}. \qquad\square\end{aligned}\end{aligned} \hspace{\stretch{1}}(1.0.151)](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Cbegin%7Baligned%7Dd%5E4+%5Cmathbf%7Bx%7D+%5Ccdot+%5Cleft%28+%7B+%5Cboldsymbol%7B%5Cpartial%7D+%5Cwedge+%5Cmathbf%7Bf%7D+%7D+%5Cright%29%26%3Dd%5E4+u%5CBigl%28+%7B+%5Cleft%28+%7B+%5Cmathbf%7Bx%7D_1+%5Cwedge+%5Cmathbf%7Bx%7D_2+%5Cwedge+%5Cmathbf%7Bx%7D_3+%5Cwedge+%5Cmathbf%7Bx%7D_4+%7D+%5Cright%29+%5Ccdot+%5Cmathbf%7Bx%7D%5Ei+%7D+%5CBigr%29+%5Ccdot+%5Cpartial_i+%5Cmathbf%7Bf%7D+%5C%5C+%26%3Dd%5E4+u%5CBigl%28+%7B%5Cleft%28+%7B+%5Cmathbf%7Bx%7D_1+%5Cwedge+%5Cmathbf%7Bx%7D_2+%5Cwedge+%5Cmathbf%7Bx%7D_3+%7D+%5Cright%29+%5Ccdot+%5Cpartial_4+%5Cmathbf%7Bf%7D-%5Cleft%28+%7B+%5Cmathbf%7Bx%7D_1+%5Cwedge+%5Cmathbf%7Bx%7D_2+%5Cwedge+%5Cmathbf%7Bx%7D_4+%7D+%5Cright%29+%5Ccdot+%5Cpartial_3+%5Cmathbf%7Bf%7D%2B%5Cleft%28+%7B+%5Cmathbf%7Bx%7D_1+%5Cwedge+%5Cmathbf%7Bx%7D_3+%5Cwedge+%5Cmathbf%7Bx%7D_4+%7D+%5Cright%29+%5Ccdot+%5Cpartial_2+%5Cmathbf%7Bf%7D-%5Cleft%28+%7B+%5Cmathbf%7Bx%7D_2+%5Cwedge+%5Cmathbf%7Bx%7D_3+%5Cwedge+%5Cmathbf%7Bx%7D_4+%7D+%5Cright%29+%5Ccdot+%5Cpartial_1+%5Cmathbf%7Bf%7D%7D+%5CBigr%29+%5C%5C+%26%3Dd%5E4+u%5CBigl%28+%7B+%5C%5C+%26%5Cquad%5Cquad+%5Cleft%28+%7B+%5Cmathbf%7Bx%7D_1+%5Cwedge+%5Cmathbf%7Bx%7D_2+%7D+%5Cright%29+%5Cmathbf%7Bx%7D_3+%5Ccdot+%5Cpartial_4+%5Cmathbf%7Bf%7D-%5Cleft%28+%7B+%5Cmathbf%7Bx%7D_1+%5Cwedge+%5Cmathbf%7Bx%7D_3+%7D+%5Cright%29+%5Cmathbf%7Bx%7D_2+%5Ccdot+%5Cpartial_4+%5Cmathbf%7Bf%7D%2B%5Cleft%28+%7B+%5Cmathbf%7Bx%7D_2+%5Cwedge+%5Cmathbf%7Bx%7D_3+%7D+%5Cright%29+%5Cmathbf%7Bx%7D_1+%5Ccdot+%5Cpartial_4+%5Cmathbf%7Bf%7D+%5C%5C+%26%5Cquad-%5Cleft%28+%7B+%5Cmathbf%7Bx%7D_1+%5Cwedge+%5Cmathbf%7Bx%7D_2+%7D+%5Cright%29+%5Cmathbf%7Bx%7D_4+%5Ccdot+%5Cpartial_3+%5Cmathbf%7Bf%7D%2B%5Cleft%28+%7B+%5Cmathbf%7Bx%7D_1+%5Cwedge+%5Cmathbf%7Bx%7D_4+%7D+%5Cright%29+%5Cmathbf%7Bx%7D_2+%5Ccdot+%5Cpartial_3+%5Cmathbf%7Bf%7D-%5Cleft%28+%7B+%5Cmathbf%7Bx%7D_2+%5Cwedge+%5Cmathbf%7Bx%7D_4+%7D+%5Cright%29+%5Cmathbf%7Bx%7D_1+%5Ccdot+%5Cpartial_3+%5Cmathbf%7Bf%7D+%5C%5C+%26%5Cquad%2B+%5Cleft%28+%7B+%5Cmathbf%7Bx%7D_1+%5Cwedge+%5Cmathbf%7Bx%7D_3+%7D+%5Cright%29+%5Cmathbf%7Bx%7D_4+%5Ccdot+%5Cpartial_2+%5Cmathbf%7Bf%7D-%5Cleft%28+%7B+%5Cmathbf%7Bx%7D_1+%5Cwedge+%5Cmathbf%7Bx%7D_4+%7D+%5Cright%29+%5Cmathbf%7Bx%7D_3+%5Ccdot+%5Cpartial_2+%5Cmathbf%7Bf%7D%2B%5Cleft%28+%7B+%5Cmathbf%7Bx%7D_3+%5Cwedge+%5Cmathbf%7Bx%7D_4+%7D+%5Cright%29+%5Cmathbf%7Bx%7D_1+%5Ccdot+%5Cpartial_2+%5Cmathbf%7Bf%7D+%5C%5C+%26%5Cquad-%5Cleft%28+%7B+%5Cmathbf%7Bx%7D_2+%5Cwedge+%5Cmathbf%7Bx%7D_3+%7D+%5Cright%29+%5Cmathbf%7Bx%7D_4+%5Ccdot+%5Cpartial_1+%5Cmathbf%7Bf%7D%2B%5Cleft%28+%7B+%5Cmathbf%7Bx%7D_2+%5Cwedge+%5Cmathbf%7Bx%7D_4+%7D+%5Cright%29+%5Cmathbf%7Bx%7D_3+%5Ccdot+%5Cpartial_1+%5Cmathbf%7Bf%7D-%5Cleft%28+%7B+%5Cmathbf%7Bx%7D_3+%5Cwedge+%5Cmathbf%7Bx%7D_4+%7D+%5Cright%29+%5Cmathbf%7Bx%7D_2+%5Ccdot+%5Cpartial_1+%5Cmathbf%7Bf%7D+%5C%5C+%26%5Cqquad%7D+%5CBigr%29+%5C%5C+%26%3Dd%5E4+u%5CBigl%28+%7B%5Cmathbf%7Bx%7D_1+%5Cwedge+%5Cmathbf%7Bx%7D_2+%5Cpartial_%7B%5B4%7D+f_%7B3%5D%7D%2B%5Cmathbf%7Bx%7D_1+%5Cwedge+%5Cmathbf%7Bx%7D_3+%5Cpartial_%7B%5B2%7D+f_%7B4%5D%7D%2B%5Cmathbf%7Bx%7D_1+%5Cwedge+%5Cmathbf%7Bx%7D_4+%5Cpartial_%7B%5B3%7D+f_%7B2%5D%7D%2B%5Cmathbf%7Bx%7D_2+%5Cwedge+%5Cmathbf%7Bx%7D_3+%5Cpartial_%7B%5B4%7D+f_%7B1%5D%7D%2B%5Cmathbf%7Bx%7D_2+%5Cwedge+%5Cmathbf%7Bx%7D_4+%5Cpartial_%7B%5B1%7D+f_%7B3%5D%7D%2B%5Cmathbf%7Bx%7D_3+%5Cwedge+%5Cmathbf%7Bx%7D_4+%5Cpartial_%7B%5B2%7D+f_%7B1%5D%7D%7D+%5CBigr%29+%5C%5C+%26%3D-+%5Cfrac%7B1%7D%7B2%7D+d%5E4+u+%5Cepsilon%5E%7Babcd%7D+%5Cmathbf%7Bx%7D_a+%5Cwedge+%5Cmathbf%7Bx%7D_b+%5Cpartial_%7Bc%7D+f_%7Bd%7D.+%5Cqquad%5Csquare%5Cend%7Baligned%7D%5Cend%7Baligned%7D+%5Chspace%7B%5Cstretch%7B1%7D%7D%281.0.151%29&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
(d) Three parameter volume, curl of bivector

(e) Four parameter volume, curl of bivector
To start, we require lemma 3. For convenience lets also write our wedge products as a single indexed quantity, as in 
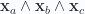

This last step uses an intermediate result from the eq. 1.0.152 expansion above, since each of the four terms has the same structure we have previously observed.
(f) Four parameter volume, curl of trivector
Using the 

Applying lemma 4 to expand the inner products within the braces we have

We can cancel those last terms using lemma 5. Using the same reverse chain rule expansion once more we have

or

The final result follows after permuting the indices slightly.
Some helpful identities
Lemma 1. Distribution of inner products
Given two blades 

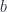

This will allow us, for example, to expand a general inner product of the form 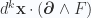
The proof is straightforward, but also mechanical. Start by expanding the wedge and dot products within a grade selection operator

Solving for 

we have

The last term above is zero since we are selecting the 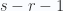


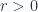
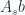

The latter multivector (with the wedge product factor) above has grades 
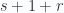
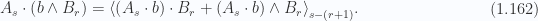
The first dot products term has grade 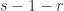


Lemma 2. Distribution of two bivectors
For vectors 
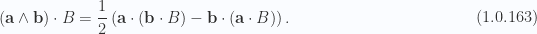
Proof follows by applying the scalar selection operator, expanding the wedge product within it, and eliminating any of the terms that cannot contribute grade zero values

Lemma 3. Inner product of trivector with bivector
Given a bivector 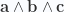


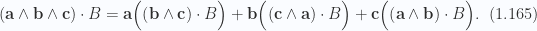
This is also problem 1.1(c) from Exercises 2.1 in [3], and submits to a dumb expansion in successive dot products with a final regrouping. With


Lemma 4. Distribution of two trivectors
Given a trivector
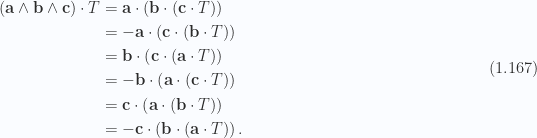
To show this, we first expand within a scalar selection operator

Now consider any single term from the scalar selection, such as the first. This can be reordered using the vector dot product identity
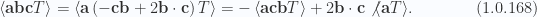
The vector-trivector product in the latter grade selection operation above contributes only bivector and quadvector terms, thus contributing nothing. This can be repeated, showing that

Substituting this back into eq. 1.0.168 proves lemma 4.
Lemma 5. Permutation of two successive dot products with trivector
Given a trivector

This and lemma 4 are clearly examples of a more general identity, but I’ll not try to prove that here. To show this one, we have
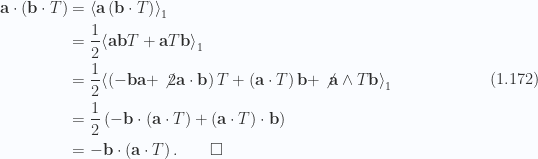
Cancellation of terms above was because they could not contribute to a grade one selection. We also employed the relation 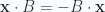
Lemma 6. Duality in a plane
For a vector

Satisfying

and

To demonstrate, we start with the expansion of

Dotting with

but dotting with
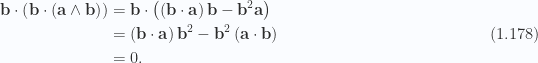
To complete the proof, we note that the product in eq. 1.177 is just the wedge squared

This duality relation can be recast with a linear denominator

or

We can use this form after scaling it appropriately to express duality in terms of the pseudoscalar.
Lemma 7. Dual vector in a three vector subspace
In the subspace spanned by 
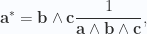
Consider the dot product of 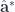
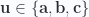
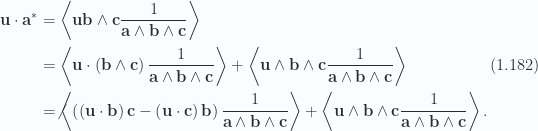
The canceled term is eliminated since it is the product of a vector and trivector producing no scalar term. Substituting 
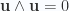

Lemma 8. Pseudoscalar selection
For grade 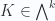
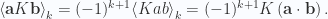
To show this, we have to consider even and odd grades separately. First for even
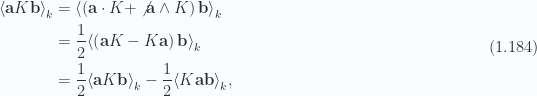
or

Similarly for odd
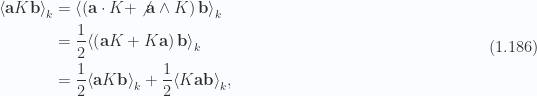
or

Adjusting for the signs completes the proof.
References
[1] John Denker. Magnetic field for a straight wire., 2014. URL http://www.av8n.com/physics/straight-wire.pdf. [Online; accessed 11-May-2014].
[2] H. Flanders. Differential Forms With Applications to the Physical Sciences. Courier Dover Publications, 1989.
[3] D. Hestenes. New Foundations for Classical Mechanics. Kluwer Academic Publishers, 1999.
[4] Peeter Joot. Collection of old notes on Stokes theorem in Geometric algebra, 2014. URL https://sites.google.com/site/peeterjoot3/math2014/bigCollectionOfPartiallyIncorrectStokesTheoremMusings.pdf.
[5] Peeter Joot. Synposis of old notes on Stokes theorem in Geometric algebra, 2014. URL https://sites.google.com/site/peeterjoot3/math2014/synopsisOfBigCollectionOfPartiallyIncorrectStokesTheoremMusings.pdf.
[6] A. Macdonald. Vector and Geometric Calculus. CreateSpace Independent Publishing Platform, 2012.
[7] M. Schwartz. Principles of Electrodynamics. Dover Publications, 1987.
[8] Michael Spivak. Calculus on manifolds, volume 1. Benjamin New York, 1965.

 was. It obviously must be related to the normal to the surface. It seemed to me that a natural way to answer this question was to consider this divergence integral over an arbitrarily parametrized volume. This turns out to be overkill, but a useful seeming digression.
was. It obviously must be related to the normal to the surface. It seemed to me that a natural way to answer this question was to consider this divergence integral over an arbitrarily parametrized volume. This turns out to be overkill, but a useful seeming digression.
 constant, and varying the remaining one. In particular, we can construct three direction vectors along these level curves, one for each parameter not held constant
constant, and varying the remaining one. In particular, we can construct three direction vectors along these level curves, one for each parameter not held constant

![\begin{aligned}d^3\mathbf{x} &= \frac{\partial {\mathbf{x}}}{\partial {a_1}} \cdot \left( \frac{\partial {\mathbf{x}}}{\partial {a_2}} \times \frac{\partial {\mathbf{x}}}{\partial {a_3}} \right) \\ &= \frac{\partial {x^\alpha}}{\partial {a_1}} \frac{\partial {x^\beta}}{\partial {a_2}} \frac{\partial {x^\gamma}}{\partial {a_3}} \epsilon_{\alpha \beta \gamma} da_1 da_2 da_3 \\ &= \frac{\partial {x^1}}{\partial {a_\alpha}} \frac{\partial {x^2}}{\partial {a_\beta}} \frac{\partial {x^3}}{\partial {a_\gamma}} \epsilon_{\alpha \beta \gamma} da_1 da_2 da_3 \\ &= \frac{\partial {x^1}}{\partial {a_{[1}}} \frac{\partial {x^2}}{\partial {a_{2}}} \frac{\partial {x^3}}{\partial {a_{3]}}} da_1 da_2 da_2 \\ &= {\left\lvert{ \frac{\partial(x^1, x^2, x^3)}{\partial (a_1, a_2, a_3)}}\right\rvert}da_1 da_2 da_3 \\ \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7Dd%5E3%5Cmathbf%7Bx%7D+%26%3D+%5Cfrac%7B%5Cpartial+%7B%5Cmathbf%7Bx%7D%7D%7D%7B%5Cpartial+%7Ba_1%7D%7D+%5Ccdot+%5Cleft%28+%5Cfrac%7B%5Cpartial+%7B%5Cmathbf%7Bx%7D%7D%7D%7B%5Cpartial+%7Ba_2%7D%7D+%5Ctimes+%5Cfrac%7B%5Cpartial+%7B%5Cmathbf%7Bx%7D%7D%7D%7B%5Cpartial+%7Ba_3%7D%7D+%5Cright%29+%5C%5C+%26%3D+%5Cfrac%7B%5Cpartial+%7Bx%5E%5Calpha%7D%7D%7B%5Cpartial+%7Ba_1%7D%7D+%5Cfrac%7B%5Cpartial+%7Bx%5E%5Cbeta%7D%7D%7B%5Cpartial+%7Ba_2%7D%7D+%5Cfrac%7B%5Cpartial+%7Bx%5E%5Cgamma%7D%7D%7B%5Cpartial+%7Ba_3%7D%7D+%5Cepsilon_%7B%5Calpha+%5Cbeta+%5Cgamma%7D+da_1+da_2+da_3+%5C%5C+%26%3D+%5Cfrac%7B%5Cpartial+%7Bx%5E1%7D%7D%7B%5Cpartial+%7Ba_%5Calpha%7D%7D+%5Cfrac%7B%5Cpartial+%7Bx%5E2%7D%7D%7B%5Cpartial+%7Ba_%5Cbeta%7D%7D+%5Cfrac%7B%5Cpartial+%7Bx%5E3%7D%7D%7B%5Cpartial+%7Ba_%5Cgamma%7D%7D+%5Cepsilon_%7B%5Calpha+%5Cbeta+%5Cgamma%7D+da_1+da_2+da_3+%5C%5C+%26%3D+%5Cfrac%7B%5Cpartial+%7Bx%5E1%7D%7D%7B%5Cpartial+%7Ba_%7B%5B1%7D%7D%7D+%5Cfrac%7B%5Cpartial+%7Bx%5E2%7D%7D%7B%5Cpartial+%7Ba_%7B2%7D%7D%7D+%5Cfrac%7B%5Cpartial+%7Bx%5E3%7D%7D%7B%5Cpartial+%7Ba_%7B3%5D%7D%7D%7D+da_1+da_2+da_2+%5C%5C+%26%3D+%7B%5Cleft%5Clvert%7B+%5Cfrac%7B%5Cpartial%28x%5E1%2C+x%5E2%2C+x%5E3%29%7D%7B%5Cpartial+%28a_1%2C+a_2%2C+a_3%29%7D%7D%5Cright%5Crvert%7Dda_1+da_2+da_3+%5C%5C+%5Cend%7Baligned%7D+&bg=fafcff&fg=2a2a2a&s=0&c=20201002)


![[a_{1-}, a_{1+}]](https://s0.wp.com/latex.php?latex=%5Ba_%7B1-%7D%2C+a_%7B1%2B%7D%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002) ,
, ![[a_{2-}, a_{2+}]](https://s0.wp.com/latex.php?latex=%5Ba_%7B2-%7D%2C+a_%7B2%2B%7D%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002) ,
, ![[a_{3-}, a_{3+}]](https://s0.wp.com/latex.php?latex=%5Ba_%7B3-%7D%2C+a_%7B3%2B%7D%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002) . Observe that the outwards normals along the
. Observe that the outwards normals along the  face is
face is  . This is
. This is
 face is
face is
 face the outward normal is
face the outward normal is
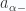 faces these are just negated. We can summarize these as
faces these are just negated. We can summarize these as

 is indexed will not matter yet, so let’s suppress it. The Jacobian determinant can be expanded along the
is indexed will not matter yet, so let’s suppress it. The Jacobian determinant can be expanded along the  column for
column for![\begin{aligned}\int d^3 \mathbf{x} \partial_3 M&=\int da_1 da_2 da_3{\left\lvert{ \frac{\partial(x^1, x^2, x^3)}{\partial (a_1, a_2, a_3)}}\right\rvert} \frac{\partial {M}}{\partial {x^3}} \\ &=\int da_1 da_2 da_3\left(\frac{\partial {x^1}}{\partial {a_{[1}}} \frac{\partial {x^2}}{\partial {a_{2}}} \frac{\partial {x^3}}{\partial {a_{3]}}} \right)\frac{\partial {M}}{\partial {x^3}} \\ &=\int da_1 da_2 da_3\left(\frac{\partial {x^1}}{\partial {a_{[1}}} \frac{\partial {x^2}}{\partial {a_{2]}}} \frac{\partial {x^3}}{\partial {a_{3}}} +\frac{\partial {x^1}}{\partial {a_{[2}}} \frac{\partial {x^2}}{\partial {a_{3]}}} \frac{\partial {x^3}}{\partial {a_{1}}} +\frac{\partial {x^1}}{\partial {a_{[3}}} \frac{\partial {x^2}}{\partial {a_{1]}}} \frac{\partial {x^3}}{\partial {a_{2}}} \right)\frac{\partial {M}}{\partial {x^3}} \\ &=\int da_1 da_2 da_3\left({\left\lvert{ \frac{\partial(x^1, x^2)}{\partial (a_1, a_2)}}\right\rvert} \frac{\partial {x^3}}{\partial {a_{3}}} +{\left\lvert{ \frac{\partial(x^1, x^2)}{\partial (a_2, a_3)}}\right\rvert} \frac{\partial {x^3}}{\partial {a_{1}}} +{\left\lvert{ \frac{\partial(x^1, x^2)}{\partial (a_3, a_1)}}\right\rvert} \frac{\partial {x^3}}{\partial {a_{2}}} \right)\frac{\partial {M}}{\partial {x^3}} \\ &=\int da_1 da_2 {\left\lvert{ \frac{\partial(x^1, x^2)}{\partial (a_1, a_2)}}\right\rvert} \int da_3 \frac{\partial {x^3}}{\partial {a_{3}}} \frac{\partial {M}}{\partial {x^3}} \\ &\qquad +\int da_2 da_3 {\left\lvert{ \frac{\partial(x^1, x^2)}{\partial (a_2, a_3)}}\right\rvert} \int da_1 \frac{\partial {x^3}}{\partial {a_{1}}} \frac{\partial {M}}{\partial {x^3}} \\ &\qquad +\int da_3 da_1 {\left\lvert{ \frac{\partial(x^1, x^2)}{\partial (a_3, a_1)}}\right\rvert} \int da_2 \frac{\partial {x^3}}{\partial {a_{2}}} \frac{\partial {M}}{\partial {x^3}} \\ &=\int da_1 da_2 {\left\lvert{ \frac{\partial(x^1, x^2)}{\partial (a_1, a_2)}}\right\rvert} \int da_3 \frac{\partial {M}}{\partial {a_{3}}} \\ &\qquad +\int da_2 da_3 {\left\lvert{ \frac{\partial(x^1, x^2)}{\partial (a_2, a_3)}}\right\rvert} \int da_1 \frac{\partial {M}}{\partial {a_{1}}} \\ &\qquad +\int da_3 da_1 {\left\lvert{ \frac{\partial(x^1, x^2)}{\partial (a_3, a_1)}}\right\rvert} \int da_2 \frac{\partial {M}}{\partial {a_{2}}} \\ &=\int da_1 da_2 {\left\lvert{ \frac{\partial(x^1, x^2)}{\partial (a_1, a_2)}}\right\rvert} \Bigl( M(a_{3+}) - M(a_{3+}) \Bigr) \\ &\qquad +\int da_2 da_3 {\left\lvert{ \frac{\partial(x^1, x^2)}{\partial (a_2, a_3)}}\right\rvert} \Bigl( M(a_{1+}) - M(a_{1+}) \Bigr) \\ &\qquad +\int da_3 da_1 {\left\lvert{ \frac{\partial(x^1, x^2)}{\partial (a_3, a_1)}}\right\rvert} \Bigl( M(a_{2+}) - M(a_{2+}) \Bigr)\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Cint+d%5E3+%5Cmathbf%7Bx%7D+%5Cpartial_3+M%26%3D%5Cint+da_1+da_2+da_3%7B%5Cleft%5Clvert%7B+%5Cfrac%7B%5Cpartial%28x%5E1%2C+x%5E2%2C+x%5E3%29%7D%7B%5Cpartial+%28a_1%2C+a_2%2C+a_3%29%7D%7D%5Cright%5Crvert%7D+%5Cfrac%7B%5Cpartial+%7BM%7D%7D%7B%5Cpartial+%7Bx%5E3%7D%7D+%5C%5C+%26%3D%5Cint+da_1+da_2+da_3%5Cleft%28%5Cfrac%7B%5Cpartial+%7Bx%5E1%7D%7D%7B%5Cpartial+%7Ba_%7B%5B1%7D%7D%7D+%5Cfrac%7B%5Cpartial+%7Bx%5E2%7D%7D%7B%5Cpartial+%7Ba_%7B2%7D%7D%7D+%5Cfrac%7B%5Cpartial+%7Bx%5E3%7D%7D%7B%5Cpartial+%7Ba_%7B3%5D%7D%7D%7D+%5Cright%29%5Cfrac%7B%5Cpartial+%7BM%7D%7D%7B%5Cpartial+%7Bx%5E3%7D%7D+%5C%5C+%26%3D%5Cint+da_1+da_2+da_3%5Cleft%28%5Cfrac%7B%5Cpartial+%7Bx%5E1%7D%7D%7B%5Cpartial+%7Ba_%7B%5B1%7D%7D%7D+%5Cfrac%7B%5Cpartial+%7Bx%5E2%7D%7D%7B%5Cpartial+%7Ba_%7B2%5D%7D%7D%7D+%5Cfrac%7B%5Cpartial+%7Bx%5E3%7D%7D%7B%5Cpartial+%7Ba_%7B3%7D%7D%7D+%2B%5Cfrac%7B%5Cpartial+%7Bx%5E1%7D%7D%7B%5Cpartial+%7Ba_%7B%5B2%7D%7D%7D+%5Cfrac%7B%5Cpartial+%7Bx%5E2%7D%7D%7B%5Cpartial+%7Ba_%7B3%5D%7D%7D%7D+%5Cfrac%7B%5Cpartial+%7Bx%5E3%7D%7D%7B%5Cpartial+%7Ba_%7B1%7D%7D%7D+%2B%5Cfrac%7B%5Cpartial+%7Bx%5E1%7D%7D%7B%5Cpartial+%7Ba_%7B%5B3%7D%7D%7D+%5Cfrac%7B%5Cpartial+%7Bx%5E2%7D%7D%7B%5Cpartial+%7Ba_%7B1%5D%7D%7D%7D+%5Cfrac%7B%5Cpartial+%7Bx%5E3%7D%7D%7B%5Cpartial+%7Ba_%7B2%7D%7D%7D+%5Cright%29%5Cfrac%7B%5Cpartial+%7BM%7D%7D%7B%5Cpartial+%7Bx%5E3%7D%7D+%5C%5C+%26%3D%5Cint+da_1+da_2+da_3%5Cleft%28%7B%5Cleft%5Clvert%7B+%5Cfrac%7B%5Cpartial%28x%5E1%2C+x%5E2%29%7D%7B%5Cpartial+%28a_1%2C+a_2%29%7D%7D%5Cright%5Crvert%7D+%5Cfrac%7B%5Cpartial+%7Bx%5E3%7D%7D%7B%5Cpartial+%7Ba_%7B3%7D%7D%7D+%2B%7B%5Cleft%5Clvert%7B+%5Cfrac%7B%5Cpartial%28x%5E1%2C+x%5E2%29%7D%7B%5Cpartial+%28a_2%2C+a_3%29%7D%7D%5Cright%5Crvert%7D+%5Cfrac%7B%5Cpartial+%7Bx%5E3%7D%7D%7B%5Cpartial+%7Ba_%7B1%7D%7D%7D+%2B%7B%5Cleft%5Clvert%7B+%5Cfrac%7B%5Cpartial%28x%5E1%2C+x%5E2%29%7D%7B%5Cpartial+%28a_3%2C+a_1%29%7D%7D%5Cright%5Crvert%7D+%5Cfrac%7B%5Cpartial+%7Bx%5E3%7D%7D%7B%5Cpartial+%7Ba_%7B2%7D%7D%7D+%5Cright%29%5Cfrac%7B%5Cpartial+%7BM%7D%7D%7B%5Cpartial+%7Bx%5E3%7D%7D+%5C%5C+%26%3D%5Cint+da_1+da_2+%7B%5Cleft%5Clvert%7B+%5Cfrac%7B%5Cpartial%28x%5E1%2C+x%5E2%29%7D%7B%5Cpartial+%28a_1%2C+a_2%29%7D%7D%5Cright%5Crvert%7D+%5Cint+da_3+%5Cfrac%7B%5Cpartial+%7Bx%5E3%7D%7D%7B%5Cpartial+%7Ba_%7B3%7D%7D%7D+%5Cfrac%7B%5Cpartial+%7BM%7D%7D%7B%5Cpartial+%7Bx%5E3%7D%7D+%5C%5C+%26%5Cqquad+%2B%5Cint+da_2+da_3+%7B%5Cleft%5Clvert%7B+%5Cfrac%7B%5Cpartial%28x%5E1%2C+x%5E2%29%7D%7B%5Cpartial+%28a_2%2C+a_3%29%7D%7D%5Cright%5Crvert%7D+%5Cint+da_1+%5Cfrac%7B%5Cpartial+%7Bx%5E3%7D%7D%7B%5Cpartial+%7Ba_%7B1%7D%7D%7D+%5Cfrac%7B%5Cpartial+%7BM%7D%7D%7B%5Cpartial+%7Bx%5E3%7D%7D+%5C%5C+%26%5Cqquad+%2B%5Cint+da_3+da_1+%7B%5Cleft%5Clvert%7B+%5Cfrac%7B%5Cpartial%28x%5E1%2C+x%5E2%29%7D%7B%5Cpartial+%28a_3%2C+a_1%29%7D%7D%5Cright%5Crvert%7D+%5Cint+da_2+%5Cfrac%7B%5Cpartial+%7Bx%5E3%7D%7D%7B%5Cpartial+%7Ba_%7B2%7D%7D%7D+%5Cfrac%7B%5Cpartial+%7BM%7D%7D%7B%5Cpartial+%7Bx%5E3%7D%7D+%5C%5C+%26%3D%5Cint+da_1+da_2+%7B%5Cleft%5Clvert%7B+%5Cfrac%7B%5Cpartial%28x%5E1%2C+x%5E2%29%7D%7B%5Cpartial+%28a_1%2C+a_2%29%7D%7D%5Cright%5Crvert%7D+%5Cint+da_3+%5Cfrac%7B%5Cpartial+%7BM%7D%7D%7B%5Cpartial+%7Ba_%7B3%7D%7D%7D+%5C%5C+%26%5Cqquad+%2B%5Cint+da_2+da_3+%7B%5Cleft%5Clvert%7B+%5Cfrac%7B%5Cpartial%28x%5E1%2C+x%5E2%29%7D%7B%5Cpartial+%28a_2%2C+a_3%29%7D%7D%5Cright%5Crvert%7D+%5Cint+da_1+%5Cfrac%7B%5Cpartial+%7BM%7D%7D%7B%5Cpartial+%7Ba_%7B1%7D%7D%7D+%5C%5C+%26%5Cqquad+%2B%5Cint+da_3+da_1+%7B%5Cleft%5Clvert%7B+%5Cfrac%7B%5Cpartial%28x%5E1%2C+x%5E2%29%7D%7B%5Cpartial+%28a_3%2C+a_1%29%7D%7D%5Cright%5Crvert%7D+%5Cint+da_2+%5Cfrac%7B%5Cpartial+%7BM%7D%7D%7B%5Cpartial+%7Ba_%7B2%7D%7D%7D+%5C%5C+%26%3D%5Cint+da_1+da_2+%7B%5Cleft%5Clvert%7B+%5Cfrac%7B%5Cpartial%28x%5E1%2C+x%5E2%29%7D%7B%5Cpartial+%28a_1%2C+a_2%29%7D%7D%5Cright%5Crvert%7D+%5CBigl%28+M%28a_%7B3%2B%7D%29+-+M%28a_%7B3%2B%7D%29+%5CBigr%29+%5C%5C+%26%5Cqquad+%2B%5Cint+da_2+da_3+%7B%5Cleft%5Clvert%7B+%5Cfrac%7B%5Cpartial%28x%5E1%2C+x%5E2%29%7D%7B%5Cpartial+%28a_2%2C+a_3%29%7D%7D%5Cright%5Crvert%7D+%5CBigl%28+M%28a_%7B1%2B%7D%29+-+M%28a_%7B1%2B%7D%29+%5CBigr%29+%5C%5C+%26%5Cqquad+%2B%5Cint+da_3+da_1+%7B%5Cleft%5Clvert%7B+%5Cfrac%7B%5Cpartial%28x%5E1%2C+x%5E2%29%7D%7B%5Cpartial+%28a_3%2C+a_1%29%7D%7D%5Cright%5Crvert%7D+%5CBigl%28+M%28a_%7B2%2B%7D%29+-+M%28a_%7B2%2B%7D%29+%5CBigr%29%5Cend%7Baligned%7D+&bg=fafcff&fg=2a2a2a&s=0&c=20201002)



 evaluated on the points of the surface for which
evaluated on the points of the surface for which 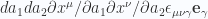 . We do the same, but subtract the integral where
. We do the same, but subtract the integral where  is evaluated on the surface
is evaluated on the surface 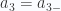 , where we dot with the area element that has the inwards normal direction on that surface. This is then done for each of the surfaces of the parallelepiped that we are integrating over.
, where we dot with the area element that has the inwards normal direction on that surface. This is then done for each of the surfaces of the parallelepiped that we are integrating over. on the
on the 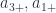 and
and  surfaces respectively we can write
surfaces respectively we can write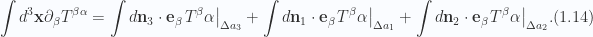

 latex a_{1+}$,
latex a_{1+}$, 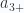 }} d^2 \sigma^\beta T^{\beta \alpha}-\int_{\text{over level surfaces
}} d^2 \sigma^\beta T^{\beta \alpha}-\int_{\text{over level surfaces  ,
,  ,
,  }} d^2 \sigma^\beta T^{\beta \alpha}\end{aligned} \hspace{\stretch{1}}(1.16)$
}} d^2 \sigma^\beta T^{\beta \alpha}\end{aligned} \hspace{\stretch{1}}(1.16)$

 .
. ,
,  ,
,  , and the duality of Maxwell’s equations in vacuum.
, and the duality of Maxwell’s equations in vacuum.


 . This is
. This is
 only one term is non-zero. For example with
only one term is non-zero. For example with  , we have just a contribution from the
, we have just a contribution from the  part of the sum
part of the sum
 is
is
 we have
we have
 matches
matches  , and value minus one for when
, and value minus one for when 
 the RHS is
the RHS is




 only one term of this sum is picked up. For example, with no loss of generality, pick
only one term of this sum is picked up. For example, with no loss of generality, pick  . We are left with only
. We are left with only

 and is zero otherwise. We can therefore summarize the evaluation of this sum as
and is zero otherwise. We can therefore summarize the evaluation of this sum as
 matrix
matrix  :
:  and that
and that  .
. . It occurred to me later that I’d seen the identity to be proven in the context of Geometric Algebra, but hadn’t recognized it in this tensor form. Basically, a wedge product can be expanded in sums of determinants, and when the dimension of the space is the same as the vector, we have a pseudoscalar times the determinant of the components.
. It occurred to me later that I’d seen the identity to be proven in the context of Geometric Algebra, but hadn’t recognized it in this tensor form. Basically, a wedge product can be expanded in sums of determinants, and when the dimension of the space is the same as the vector, we have a pseudoscalar times the determinant of the components.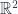 , let’s take the wedge product of a pair of vectors. As preparation for the relativistic
, let’s take the wedge product of a pair of vectors. As preparation for the relativistic 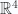 case We won’t require an orthonormal basis, but express the vector in terms of a reciprocal frame and the associated components
case We won’t require an orthonormal basis, but express the vector in terms of a reciprocal frame and the associated components





 .
.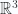 relation that we want to prove, which had an antisymmetric tensor factor for the determinant. Observe that we get the determinant by picking off the
relation that we want to prove, which had an antisymmetric tensor factor for the determinant. Observe that we get the determinant by picking off the  . To get an antisymmetric tensor times the determinant, we have only to dot with a different pseudoscalar (one that differs by a possible sign due to permutation of the indexes). That is
. To get an antisymmetric tensor times the determinant, we have only to dot with a different pseudoscalar (one that differs by a possible sign due to permutation of the indexes). That is![\begin{aligned}(e^t \wedge e^s) \cdot (a \wedge b)&=a^i b^j (e^t \wedge e^s) \cdot (e_i \wedge e_j) \\ &=a^i b^j\left( {\delta^{s}}_i {\delta^{t}}_j-{\delta^{t}}_i {\delta^{s}}_j \right) \\ &=a^i b^j{\delta^{[t}}_j {\delta^{s]}}_i \\ &=a^i b^j{\delta^{t}}_{[j} {\delta^{s}}_{i]} \\ &=a^{[i} b^{j]}{\delta^{t}}_{j} {\delta^{s}}_{i} \\ &=a^{[s} b^{t]}\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%28e%5Et+%5Cwedge+e%5Es%29+%5Ccdot+%28a+%5Cwedge+b%29%26%3Da%5Ei+b%5Ej+%28e%5Et+%5Cwedge+e%5Es%29+%5Ccdot+%28e_i+%5Cwedge+e_j%29+%5C%5C+%26%3Da%5Ei+b%5Ej%5Cleft%28+%7B%5Cdelta%5E%7Bs%7D%7D_i+%7B%5Cdelta%5E%7Bt%7D%7D_j-%7B%5Cdelta%5E%7Bt%7D%7D_i+%7B%5Cdelta%5E%7Bs%7D%7D_j++%5Cright%29+%5C%5C+%26%3Da%5Ei+b%5Ej%7B%5Cdelta%5E%7B%5Bt%7D%7D_j+%7B%5Cdelta%5E%7Bs%5D%7D%7D_i+%5C%5C+%26%3Da%5Ei+b%5Ej%7B%5Cdelta%5E%7Bt%7D%7D_%7B%5Bj%7D+%7B%5Cdelta%5E%7Bs%7D%7D_%7Bi%5D%7D+%5C%5C+%26%3Da%5E%7B%5Bi%7D+b%5E%7Bj%5D%7D%7B%5Cdelta%5E%7Bt%7D%7D_%7Bj%7D+%7B%5Cdelta%5E%7Bs%7D%7D_%7Bi%7D+%5C%5C+%26%3Da%5E%7B%5Bs%7D+b%5E%7Bt%5D%7D%5Cend%7Baligned%7D+&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
 and
and  we have
we have

 and
and  , and summing antisymmetrically over these. That is
, and summing antisymmetrically over these. That is
![\begin{aligned}\boxed{A^{a s} A^{b t} \epsilon_{a b} =A^{1 i} A^{2 j} {\delta^{[t}}_j {\delta^{s]}}_i =\epsilon^{s t} \text{Det} {\left\lVert{A^{ij}}\right\rVert},}\end{aligned} \hspace{\stretch{1}}(2.30)](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Cboxed%7BA%5E%7Ba+s%7D+A%5E%7Bb+t%7D+%5Cepsilon_%7Ba+b%7D+%3DA%5E%7B1+i%7D+A%5E%7B2+j%7D+%7B%5Cdelta%5E%7B%5Bt%7D%7D_j+%7B%5Cdelta%5E%7Bs%5D%7D%7D_i+%3D%5Cepsilon%5E%7Bs+t%7D+%5Ctext%7BDet%7D+%7B%5Cleft%5ClVert%7BA%5E%7Bij%7D%7D%5Cright%5CrVert%7D%2C%7D%5Cend%7Baligned%7D+%5Chspace%7B%5Cstretch%7B1%7D%7D%282.30%29&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![\begin{aligned}(e^u \wedge e^t \wedge e^s) \cdot ( a \wedge b \wedge c)&=a^i b^j c^k(e^u \wedge e^t \wedge e^s) \cdot (e_i \wedge e_j \wedge e_k) \\ &=a^i b^j c^k{\delta^{[u}}_k{\delta^{t}}_j{\delta^{s]}}_i \\ &=a^{[s} b^t c^{u]}\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%28e%5Eu+%5Cwedge+e%5Et+%5Cwedge+e%5Es%29+%5Ccdot+%28+a+%5Cwedge+b+%5Cwedge+c%29%26%3Da%5Ei+b%5Ej+c%5Ek%28e%5Eu+%5Cwedge+e%5Et+%5Cwedge+e%5Es%29+%5Ccdot+%28e_i+%5Cwedge+e_j+%5Cwedge+e_k%29+%5C%5C+%26%3Da%5Ei+b%5Ej+c%5Ek%7B%5Cdelta%5E%7B%5Bu%7D%7D_k%7B%5Cdelta%5E%7Bt%7D%7D_j%7B%5Cdelta%5E%7Bs%5D%7D%7D_i+%5C%5C+%26%3Da%5E%7B%5Bs%7D+b%5Et+c%5E%7Bu%5D%7D%5Cend%7Baligned%7D+&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
 we have
we have![\begin{aligned}(e^u \wedge e^t \wedge e^s) \cdot ( a \wedge b \wedge c)=A^{1 i} A^{2 j} A^{3 k}{\delta^{[u}}_k{\delta^{t}}_j{\delta^{s]}}_i\end{aligned} \hspace{\stretch{1}}(2.31)](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%28e%5Eu+%5Cwedge+e%5Et+%5Cwedge+e%5Es%29+%5Ccdot+%28+a+%5Cwedge+b+%5Cwedge+c%29%3DA%5E%7B1+i%7D+A%5E%7B2+j%7D+A%5E%7B3+k%7D%7B%5Cdelta%5E%7B%5Bu%7D%7D_k%7B%5Cdelta%5E%7Bt%7D%7D_j%7B%5Cdelta%5E%7Bs%5D%7D%7D_i%5Cend%7Baligned%7D+%5Chspace%7B%5Cstretch%7B1%7D%7D%282.31%29&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![\begin{aligned}\boxed{\epsilon^{s t u} \text{Det} {\left\lVert{A^{ij}}\right\rVert}=A^{1 i} A^{2 j} A^{3 k}{\delta^{[u}}_k{\delta^{t}}_j{\delta^{s]}}_i=\epsilon_{a b c} A^{a s} A^{b t} A^{c u}.}\end{aligned} \hspace{\stretch{1}}(2.32)](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Cboxed%7B%5Cepsilon%5E%7Bs+t+u%7D+%5Ctext%7BDet%7D+%7B%5Cleft%5ClVert%7BA%5E%7Bij%7D%7D%5Cright%5CrVert%7D%3DA%5E%7B1+i%7D+A%5E%7B2+j%7D+A%5E%7B3+k%7D%7B%5Cdelta%5E%7B%5Bu%7D%7D_k%7B%5Cdelta%5E%7Bt%7D%7D_j%7B%5Cdelta%5E%7Bs%5D%7D%7D_i%3D%5Cepsilon_%7Ba+b+c%7D+A%5E%7Ba+s%7D+A%5E%7Bb+t%7D+A%5E%7Bc+u%7D.%7D%5Cend%7Baligned%7D+%5Chspace%7B%5Cstretch%7B1%7D%7D%282.32%29&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![\begin{aligned}(e^v \wedge e^u \wedge e^t \wedge e^s) \cdot ( a \wedge b \wedge c \wedge d)&=a^i b^j c^k d^l(e^v \wedge e^u \wedge e^t \wedge e^s) \cdot (e_i \wedge e_j \wedge e_k \wedge e_l) \\ &=a^i b^j c^k d^l{\delta^{[v}}_l{\delta^{u}}_k{\delta^{t}}_j{\delta^{s]}}_i \\ &=a^{[s} b^t c^{u} d^{v]}.\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%28e%5Ev+%5Cwedge+e%5Eu+%5Cwedge+e%5Et+%5Cwedge+e%5Es%29+%5Ccdot+%28+a+%5Cwedge+b+%5Cwedge+c+%5Cwedge+d%29%26%3Da%5Ei+b%5Ej+c%5Ek+d%5El%28e%5Ev+%5Cwedge+e%5Eu+%5Cwedge+e%5Et+%5Cwedge+e%5Es%29+%5Ccdot+%28e_i+%5Cwedge+e_j+%5Cwedge+e_k+%5Cwedge+e_l%29+%5C%5C+%26%3Da%5Ei+b%5Ej+c%5Ek+d%5El%7B%5Cdelta%5E%7B%5Bv%7D%7D_l%7B%5Cdelta%5E%7Bu%7D%7D_k%7B%5Cdelta%5E%7Bt%7D%7D_j%7B%5Cdelta%5E%7Bs%5D%7D%7D_i+%5C%5C+%26%3Da%5E%7B%5Bs%7D+b%5Et+c%5E%7Bu%7D+d%5E%7Bv%5D%7D.%5Cend%7Baligned%7D+&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
 and
and  , and
, and  , and
, and  we have
we have![\begin{aligned}\boxed{\epsilon^{s t u v} \text{Det} {\left\lVert{A^{ij}}\right\rVert}=A^{0 i} A^{1 j} A^{2 k} A^{3 l}{\delta^{[v}}_l{\delta^{u}}_k{\delta^{t}}_j{\delta^{s]}}_i=\epsilon_{a b c d} A^{a s} A^{b t} A^{c u} A^{d v}.}\end{aligned} \hspace{\stretch{1}}(2.33)](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Cboxed%7B%5Cepsilon%5E%7Bs+t+u+v%7D+%5Ctext%7BDet%7D+%7B%5Cleft%5ClVert%7BA%5E%7Bij%7D%7D%5Cright%5CrVert%7D%3DA%5E%7B0+i%7D+A%5E%7B1+j%7D+A%5E%7B2+k%7D+A%5E%7B3+l%7D%7B%5Cdelta%5E%7B%5Bv%7D%7D_l%7B%5Cdelta%5E%7Bu%7D%7D_k%7B%5Cdelta%5E%7Bt%7D%7D_j%7B%5Cdelta%5E%7Bs%5D%7D%7D_i%3D%5Cepsilon_%7Ba+b+c+d%7D+A%5E%7Ba+s%7D+A%5E%7Bb+t%7D+A%5E%7Bc+u%7D+A%5E%7Bd+v%7D.%7D%5Cend%7Baligned%7D+%5Chspace%7B%5Cstretch%7B1%7D%7D%282.33%29&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
 must be a permutation of
must be a permutation of  for a non-zero result, we must have
for a non-zero result, we must have

 , since they are paired.
, since they are paired. . For the
. For the 






 is invariant under rotations.
is invariant under rotations.


 , which gives us
, which gives us
 , we have shown that
, we have shown that  is invariant under Lorentz transformations.
is invariant under Lorentz transformations.
 (sanity check of sign:
(sanity check of sign:  ).
).
 , and raise and lower all the indexes in 2.46 for
, and raise and lower all the indexes in 2.46 for

 both are therefore invariant under Lorentz transformation.
both are therefore invariant under Lorentz transformation. if
if 
 is invariant under Lorentz transformations. Consider the polynomial of
is invariant under Lorentz transformations. Consider the polynomial of  , also called the characteristic polynomial of the matrix
, also called the characteristic polynomial of the matrix  . Find the coefficients of the expansion of
. Find the coefficients of the expansion of 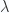 in terms of the components of
in terms of the components of  and
and  are Lorentz invariant.
are Lorentz invariant.
 , and
, and  . Let’s reflect briefly on why this determinant is unit valued. We have
. Let’s reflect briefly on why this determinant is unit valued. We have


 we have
we have
 labeling.
labeling. , and
, and  , and gave that matrix unit determinant. That
, and gave that matrix unit determinant. That  looks like it is equivalent to my
looks like it is equivalent to my  , except that the one in the course notes is loose when it comes to lower and upper indexes since it gives
, except that the one in the course notes is loose when it comes to lower and upper indexes since it gives  .
.
 ) to be the matrix with unit determinant. Having cleared the index upper and lower confusion I had trying to reconcile the class notes with the rules for index manipulation, let’s now consider the Lorentz transformation of a lower index rank 2 tensor (not necessarily antisymmetric or symmetric)
) to be the matrix with unit determinant. Having cleared the index upper and lower confusion I had trying to reconcile the class notes with the rules for index manipulation, let’s now consider the Lorentz transformation of a lower index rank 2 tensor (not necessarily antisymmetric or symmetric)
 is
is

 , or
, or  . This means we have
. This means we have


 coefficient is just
coefficient is just  .
. terms can be seen to be zero. For example, the first one is
terms can be seen to be zero. For example, the first one is
![\begin{aligned}-\frac{1}{{24}} \epsilon^{s t u v} \epsilon_{a b c d} {\delta^c}_u {F^d}_v {F^a}_s {F^b}_t &=-\frac{1}{{24}} \epsilon^{u s t v} \epsilon_{u a b d} {F^d}_v {F^a}_s {F^b}_t \\ &=-\frac{1}{{24}} \delta^{[s}_a\delta^{t}_b\delta^{v]}_d{F^d}_v {F^a}_s {F^b}_t \\ &=-\frac{1}{{24}} {F^a}_{[s}{F^b}_{t}{F^d}_{v]} \\ \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D-%5Cfrac%7B1%7D%7B%7B24%7D%7D+%5Cepsilon%5E%7Bs+t+u+v%7D+%5Cepsilon_%7Ba+b+c+d%7D+%7B%5Cdelta%5Ec%7D_u+%7BF%5Ed%7D_v+%7BF%5Ea%7D_s+%7BF%5Eb%7D_t+%26%3D-%5Cfrac%7B1%7D%7B%7B24%7D%7D+%5Cepsilon%5E%7Bu+s+t+v%7D+%5Cepsilon_%7Bu+a+b+d%7D+%7BF%5Ed%7D_v+%7BF%5Ea%7D_s+%7BF%5Eb%7D_t++%5C%5C+%26%3D-%5Cfrac%7B1%7D%7B%7B24%7D%7D+%5Cdelta%5E%7B%5Bs%7D_a%5Cdelta%5E%7Bt%7D_b%5Cdelta%5E%7Bv%5D%7D_d%7BF%5Ed%7D_v+%7BF%5Ea%7D_s+%7BF%5Eb%7D_t++%5C%5C+%26%3D-%5Cfrac%7B1%7D%7B%7B24%7D%7D+%7BF%5Ea%7D_%7B%5Bs%7D%7BF%5Eb%7D_%7Bt%7D%7BF%5Ed%7D_%7Bv%5D%7D+%5C%5C+%5Cend%7Baligned%7D+&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
 factor, let’s just expand this antisymmetric sum
factor, let’s just expand this antisymmetric sum![\begin{aligned}{F^a}_{[a}{F^b}_{b}{F^d}_{d]}&={F^a}_{a}{F^b}_{b}{F^d}_{d}+{F^a}_{d}{F^b}_{a}{F^d}_{b}+{F^a}_{b}{F^b}_{d}{F^d}_{a}-{F^a}_{a}{F^b}_{d}{F^d}_{b}-{F^a}_{d}{F^b}_{b}{F^d}_{a}-{F^a}_{b}{F^b}_{a}{F^d}_{d} \\ &={F^a}_{d}{F^b}_{a}{F^d}_{b}+{F^a}_{b}{F^b}_{d}{F^d}_{a} \\ \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%7BF%5Ea%7D_%7B%5Ba%7D%7BF%5Eb%7D_%7Bb%7D%7BF%5Ed%7D_%7Bd%5D%7D%26%3D%7BF%5Ea%7D_%7Ba%7D%7BF%5Eb%7D_%7Bb%7D%7BF%5Ed%7D_%7Bd%7D%2B%7BF%5Ea%7D_%7Bd%7D%7BF%5Eb%7D_%7Ba%7D%7BF%5Ed%7D_%7Bb%7D%2B%7BF%5Ea%7D_%7Bb%7D%7BF%5Eb%7D_%7Bd%7D%7BF%5Ed%7D_%7Ba%7D-%7BF%5Ea%7D_%7Ba%7D%7BF%5Eb%7D_%7Bd%7D%7BF%5Ed%7D_%7Bb%7D-%7BF%5Ea%7D_%7Bd%7D%7BF%5Eb%7D_%7Bb%7D%7BF%5Ed%7D_%7Ba%7D-%7BF%5Ea%7D_%7Bb%7D%7BF%5Eb%7D_%7Ba%7D%7BF%5Ed%7D_%7Bd%7D+%5C%5C+%26%3D%7BF%5Ea%7D_%7Bd%7D%7BF%5Eb%7D_%7Ba%7D%7BF%5Ed%7D_%7Bb%7D%2B%7BF%5Ea%7D_%7Bb%7D%7BF%5Eb%7D_%7Bd%7D%7BF%5Ed%7D_%7Ba%7D+%5C%5C+%5Cend%7Baligned%7D+&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
 factor. Consider the first part of this remaining part of the sum. Employing the metric tensor, to raise indexes so that the antisymmetry of
factor. Consider the first part of this remaining part of the sum. Employing the metric tensor, to raise indexes so that the antisymmetry of  can be utilized, and then finally relabeling all the dummy indexes we have
can be utilized, and then finally relabeling all the dummy indexes we have
 coefficient (
coefficient ( )
)![\begin{aligned}&\epsilon^{s t u v} \epsilon_{a b c d} \Bigl({\delta^c}_u {\delta^d}_v {F^a}_s {F^b}_t +{\delta^a}_s {F^b}_t {\delta^c}_u {F^d}_v +{\delta^b}_t {F^a}_s {\delta^d}_v {F^c}_u \\ &\qquad +{\delta^b}_t {F^a}_s {\delta^c}_u {F^d}_v +{\delta^a}_s {F^b}_t {\delta^d}_v {F^c}_u + {\delta^a}_s {\delta^b}_t {F^c}_u {F^d}_v \Bigr) \\ &=\epsilon^{s t u v} \epsilon_{a b u v} {F^a}_s {F^b}_t +\epsilon^{s t u v} \epsilon_{s b u d} {F^b}_t {F^d}_v +\epsilon^{s t u v} \epsilon_{a t c v} {F^a}_s {F^c}_u \\ &\qquad +\epsilon^{s t u v} \epsilon_{a t u d} {F^a}_s {F^d}_v +\epsilon^{s t u v} \epsilon_{s b c v} {F^b}_t {F^c}_u + \epsilon^{s t u v} \epsilon_{s t c d} {F^c}_u {F^d}_v \\ &=\epsilon^{s t u v} \epsilon_{a b u v} {F^a}_s {F^b}_t +\epsilon^{t v s u } \epsilon_{b d s u} {F^b}_t {F^d}_v +\epsilon^{s u t v} \epsilon_{a c t v} {F^a}_s {F^c}_u \\ &\qquad +\epsilon^{s v t u} \epsilon_{a d t u} {F^a}_s {F^d}_v +\epsilon^{t u s v} \epsilon_{b c s v} {F^b}_t {F^c}_u + \epsilon^{u v s t} \epsilon_{c d s t} {F^c}_u {F^d}_v \\ &=6\epsilon^{s t u v} \epsilon_{a b u v} {F^a}_s {F^b}_t \\ &=6 (2){\delta^{[s}}_a{\delta^{t]}}_b{F^a}_s {F^b}_t \\ &=12{F^a}_{[a} {F^b}_{b]} \\ &=12( {F^a}_{a} {F^b}_{b} - {F^a}_{b} {F^b}_{a} ) \\ &=-12 {F^a}_{b} {F^b}_{a} \\ &=-12 F^{a b} F_{b a} \\ &=12 F^{a b} F_{a b}\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%26%5Cepsilon%5E%7Bs+t+u+v%7D+%5Cepsilon_%7Ba+b+c+d%7D+%5CBigl%28%7B%5Cdelta%5Ec%7D_u+%7B%5Cdelta%5Ed%7D_v+%7BF%5Ea%7D_s+%7BF%5Eb%7D_t+%2B%7B%5Cdelta%5Ea%7D_s+%7BF%5Eb%7D_t+%7B%5Cdelta%5Ec%7D_u+%7BF%5Ed%7D_v+%2B%7B%5Cdelta%5Eb%7D_t+%7BF%5Ea%7D_s+%7B%5Cdelta%5Ed%7D_v+%7BF%5Ec%7D_u++%5C%5C+%26%5Cqquad+%2B%7B%5Cdelta%5Eb%7D_t+%7BF%5Ea%7D_s+%7B%5Cdelta%5Ec%7D_u+%7BF%5Ed%7D_v+%2B%7B%5Cdelta%5Ea%7D_s+%7BF%5Eb%7D_t+%7B%5Cdelta%5Ed%7D_v+%7BF%5Ec%7D_u+%2B+%7B%5Cdelta%5Ea%7D_s+%7B%5Cdelta%5Eb%7D_t++%7BF%5Ec%7D_u+%7BF%5Ed%7D_v+%5CBigr%29+%5C%5C+%26%3D%5Cepsilon%5E%7Bs+t+u+v%7D+%5Cepsilon_%7Ba+b+u+v%7D+++%7BF%5Ea%7D_s+%7BF%5Eb%7D_t+%2B%5Cepsilon%5E%7Bs+t+u+v%7D+%5Cepsilon_%7Bs+b+u+d%7D++%7BF%5Eb%7D_t++%7BF%5Ed%7D_v+%2B%5Cepsilon%5E%7Bs+t+u+v%7D+%5Cepsilon_%7Ba+t+c+v%7D++%7BF%5Ea%7D_s++%7BF%5Ec%7D_u++%5C%5C+%26%5Cqquad+%2B%5Cepsilon%5E%7Bs+t+u+v%7D+%5Cepsilon_%7Ba+t+u+d%7D++%7BF%5Ea%7D_s++%7BF%5Ed%7D_v+%2B%5Cepsilon%5E%7Bs+t+u+v%7D+%5Cepsilon_%7Bs+b+c+v%7D++%7BF%5Eb%7D_t++%7BF%5Ec%7D_u+%2B+%5Cepsilon%5E%7Bs+t+u+v%7D+%5Cepsilon_%7Bs+t+c+d%7D++++%7BF%5Ec%7D_u+%7BF%5Ed%7D_v+%5C%5C+%26%3D%5Cepsilon%5E%7Bs+t+u+v%7D+%5Cepsilon_%7Ba+b+u+v%7D+++%7BF%5Ea%7D_s+%7BF%5Eb%7D_t+%2B%5Cepsilon%5E%7Bt+v+s+u+%7D+%5Cepsilon_%7Bb+d+s+u%7D++%7BF%5Eb%7D_t++%7BF%5Ed%7D_v+%2B%5Cepsilon%5E%7Bs+u+t+v%7D+%5Cepsilon_%7Ba+c+t+v%7D++%7BF%5Ea%7D_s++%7BF%5Ec%7D_u++%5C%5C+%26%5Cqquad+%2B%5Cepsilon%5E%7Bs+v+t+u%7D+%5Cepsilon_%7Ba+d+t+u%7D++%7BF%5Ea%7D_s++%7BF%5Ed%7D_v+%2B%5Cepsilon%5E%7Bt+u+s+v%7D+%5Cepsilon_%7Bb+c+s+v%7D++%7BF%5Eb%7D_t++%7BF%5Ec%7D_u+%2B+%5Cepsilon%5E%7Bu+v+s+t%7D+%5Cepsilon_%7Bc+d+s+t%7D++++%7BF%5Ec%7D_u+%7BF%5Ed%7D_v+%5C%5C+%26%3D6%5Cepsilon%5E%7Bs+t+u+v%7D+%5Cepsilon_%7Ba+b+u+v%7D+%7BF%5Ea%7D_s+%7BF%5Eb%7D_t++%5C%5C+%26%3D6+%282%29%7B%5Cdelta%5E%7B%5Bs%7D%7D_a%7B%5Cdelta%5E%7Bt%5D%7D%7D_b%7BF%5Ea%7D_s+%7BF%5Eb%7D_t++%5C%5C+%26%3D12%7BF%5Ea%7D_%7B%5Ba%7D+%7BF%5Eb%7D_%7Bb%5D%7D++%5C%5C+%26%3D12%28+%7BF%5Ea%7D_%7Ba%7D+%7BF%5Eb%7D_%7Bb%7D+-+%7BF%5Ea%7D_%7Bb%7D+%7BF%5Eb%7D_%7Ba%7D+%29+%5C%5C+%26%3D-12+%7BF%5Ea%7D_%7Bb%7D+%7BF%5Eb%7D_%7Ba%7D+%5C%5C+%26%3D-12+F%5E%7Ba+b%7D+F_%7Bb+a%7D+%5C%5C+%26%3D12+F%5E%7Ba+b%7D+F_%7Ba+b%7D%5Cend%7Baligned%7D+&bg=fafcff&fg=2a2a2a&s=0&c=20201002)


 easily by inspection
easily by inspection

 and
and 


 to solve the Lorentz force equation in parametric form. When
to solve the Lorentz force equation in parametric form. When  we had real eigenvalues and an orthogonal diagonalization when
we had real eigenvalues and an orthogonal diagonalization when  . For the
. For the  , we had a two purely imaginary eigenvalues, and when
, we had a two purely imaginary eigenvalues, and when  this was a Hermitian diagonalization. For the general case, when one of
this was a Hermitian diagonalization. For the general case, when one of 
 we have
we have  , a Lorentz invariant. This must mean that
, a Lorentz invariant. This must mean that  only depends on the values of
only depends on the values of  at the “boundary” of spacetime (e.g. the “surface” depicted on page 105 of the notes) and hence does not affect the equations of motion for the electromagnetic field.
at the “boundary” of spacetime (e.g. the “surface” depicted on page 105 of the notes) and hence does not affect the equations of motion for the electromagnetic field.


 , where
, where  is the dual electromagnetic stress tensor. Replacing
is the dual electromagnetic stress tensor. Replacing  is known as “electric-magnetic duality”. Explain this name by considering the transformation in terms of
is known as “electric-magnetic duality”. Explain this name by considering the transformation in terms of  and
and  in terms of
in terms of 
 , and
, and  .
.
 and
and  .
.


 result? Other than that we have the same sort of structure for the tensor with
result? Other than that we have the same sort of structure for the tensor with 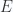 and
and 

 due to units differences), so it appears the signs above are all kosher.
due to units differences), so it appears the signs above are all kosher.
![\begin{aligned}\epsilon^{i j k l} \partial_j \tilde{F}_{k l} &=\epsilon^{i j k l} \partial_j \frac{1}{{2}} \epsilon_{k l a b} F^{a b} \\ &=\frac{1}{{2}} \epsilon^{k l i j} \epsilon_{k l a b} \partial_j F^{a b} \\ &=\frac{1}{{2}} (2!) {\delta^i}_{[a} {\delta^j}_{b]} \partial_j F^{a b} \\ &=\partial_j (F^{i j} - F^{j i} ) \\ &=2 \partial_j F^{i j} .\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Cepsilon%5E%7Bi+j+k+l%7D+%5Cpartial_j+%5Ctilde%7BF%7D_%7Bk+l%7D+%26%3D%5Cepsilon%5E%7Bi+j+k+l%7D+%5Cpartial_j+%5Cfrac%7B1%7D%7B%7B2%7D%7D+%5Cepsilon_%7Bk+l+a+b%7D+F%5E%7Ba+b%7D+%5C%5C+%26%3D%5Cfrac%7B1%7D%7B%7B2%7D%7D+%5Cepsilon%5E%7Bk+l+i+j%7D+%5Cepsilon_%7Bk+l+a+b%7D+%5Cpartial_j+F%5E%7Ba+b%7D+%5C%5C+%26%3D%5Cfrac%7B1%7D%7B%7B2%7D%7D+%282%21%29+%7B%5Cdelta%5Ei%7D_%7B%5Ba%7D+%7B%5Cdelta%5Ej%7D_%7Bb%5D%7D+%5Cpartial_j+F%5E%7Ba+b%7D+%5C%5C+%26%3D%5Cpartial_j+%28F%5E%7Bi+j%7D+-+F%5E%7Bj+i%7D+%29+%5C%5C+%26%3D2+%5Cpartial_j+F%5E%7Bi+j%7D+.%5Cend%7Baligned%7D+&bg=fafcff&fg=2a2a2a&s=0&c=20201002)

 .
. given further down that same page, and the explicit form of the
given further down that same page, and the explicit form of the  (say, corresponding to motion in the positive
(say, corresponding to motion in the positive  direction with speed
direction with speed  ) to derive the transformation law of the fields
) to derive the transformation law of the fields 


 , we can express the electromagnetic strength tensor transformation as
, we can express the electromagnetic strength tensor transformation as
 , which violates our conventions on mixed upper and lower indexes, but the end result 3.80 is the same.
, which violates our conventions on mixed upper and lower indexes, but the end result 3.80 is the same.



 , we have
, we have

 , write
, write  ,
,  , allowing a compact description of the field transformation
, allowing a compact description of the field transformation
 is
is
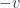 direction
direction

 this is
this is
 when I initially did (this ungraded problem) in problem set 2. That sign error should have been obvious by considering the
when I initially did (this ungraded problem) in problem set 2. That sign error should have been obvious by considering the  case which would have mysteriously resulted in inversion of all the coordinates of the observed electric field.
case which would have mysteriously resulted in inversion of all the coordinates of the observed electric field. in perpendicular
in perpendicular  of that frame relative to the “stationary” frame.
of that frame relative to the “stationary” frame.

 . Under transformation of coordinates
. Under transformation of coordinates  , with
, with  , this becomes
, this becomes
 . That is for some eigenvalue
. That is for some eigenvalue 


 and that this difference of matrices must have a zero determinant
and that this difference of matrices must have a zero determinant
 for any Lorentz transformation
for any Lorentz transformation  we have
we have
 . Observe that the characteristic equation is Lorentz invariant for any
. Observe that the characteristic equation is Lorentz invariant for any 

 , as in this problem, we must have
, as in this problem, we must have  in all frames, and the two non-zero eigenvalues of our characteristic polynomial are simply
in all frames, and the two non-zero eigenvalues of our characteristic polynomial are simply
 in one frame, we must also have
in one frame, we must also have  in another frame, still maintaining perpendicular fields. In particular if
in another frame, still maintaining perpendicular fields. In particular if  we maintain real eigenvalues. Similarly if
we maintain real eigenvalues. Similarly if  in some frame, we must always have imaginary eigenvalues, and this is also true in the
in some frame, we must always have imaginary eigenvalues, and this is also true in the  case.
case.  is zero, provided the invariants discussed are maintained.
is zero, provided the invariants discussed are maintained. and
and  .
.
 are the direction cosines of
are the direction cosines of  . We will want to compute the components of
. We will want to compute the components of 



 , but this is just zero. So we have
, but this is just zero. So we have  . So our cross products terms are just
. So our cross products terms are just

 . In coordinates from 3.117 this supplies us three sets of equations. These are
. In coordinates from 3.117 this supplies us three sets of equations. These are
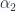 or
or  is zero. Perhaps there are solutions with
is zero. Perhaps there are solutions with  too, but inspection shows that
too, but inspection shows that  nicely kills off the first equation. Since
nicely kills off the first equation. Since  , that also implies that we are left with
, that also implies that we are left with

 solving the problem for the
solving the problem for the  case up to an adjustable constant
case up to an adjustable constant  . That constant comes with constraints however, since we must also have our cosine
. That constant comes with constraints however, since we must also have our cosine  . Expressed another way, the magnitude of the boost velocity is constrained by the relation
. Expressed another way, the magnitude of the boost velocity is constrained by the relation

 since we see this is required for a physically realizable velocity. Boosting in this direction will reduce our problem to one that has only the magnetic field component.
since we see this is required for a physically realizable velocity. Boosting in this direction will reduce our problem to one that has only the magnetic field component. . In this case, if we write out our equations for the transformed magnetic field and require these to separately equal zero, we have
. In this case, if we write out our equations for the transformed magnetic field and require these to separately equal zero, we have


 , we have as before, constraints on the allowable values of
, we have as before, constraints on the allowable values of 
 , yielding a boost direction of
, yielding a boost direction of
 is required for a physically realizable velocity if that velocity is entirely perpendicular to the fields.
is required for a physically realizable velocity if that velocity is entirely perpendicular to the fields. for a particle moving with constant velocity (considered in class, p. 100-101 of notes) is conserved
for a particle moving with constant velocity (considered in class, p. 100-101 of notes) is conserved  . Give a physical interpretation of this conservation law, for example by integrating
. Give a physical interpretation of this conservation law, for example by integrating  over some spacetime region and giving an integral form to the conservation law (
over some spacetime region and giving an integral form to the conservation law (
 represents constant motion we have
represents constant motion we have





 ).
).


 is the three-volume element perpendicular to a
is the three-volume element perpendicular to a  plane. These volume elements are detailed generally in the text [2], however, they do note that one special case specifically
plane. These volume elements are detailed generally in the text [2], however, they do note that one special case specifically  , the element of the three-dimensional (spatial) volume “normal” to hyperplanes
, the element of the three-dimensional (spatial) volume “normal” to hyperplanes  .
.
 . Are there specific orientations required by the metric. To be precise we’d have to calculate the determinants detailed in the text, and then do the duality transformations.
. Are there specific orientations required by the metric. To be precise we’d have to calculate the determinants detailed in the text, and then do the duality transformations.




 dependence will be implied.
dependence will be implied.

 is required for the energy momentum tensor. This is
is required for the energy momentum tensor. This is

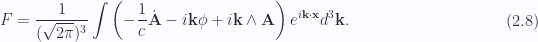


 .
.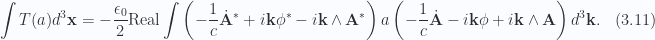
 commutes with spatial bivectors and anticommutes with spatial vectors, and writing
commutes with spatial bivectors and anticommutes with spatial vectors, and writing  , one has
, one has
 , one could write
, one could write

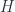
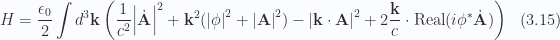
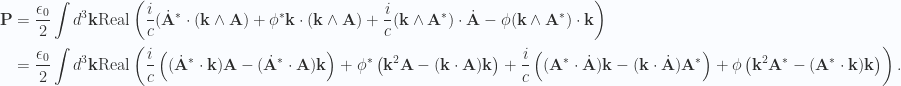

 . There is no reason to assume that will be the case. In the discrete Fourier series treatment, a gauge transformation allowed for elimination of
. There is no reason to assume that will be the case. In the discrete Fourier series treatment, a gauge transformation allowed for elimination of  , and this implied
, and this implied 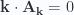 or
or  constant. We will probably have a similar result here, eliminating most of the terms in (3.15) and (3.16). Except for the constant
constant. We will probably have a similar result here, eliminating most of the terms in (3.15) and (3.16). Except for the constant 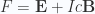 , where
, where 
 acting as a non-commutatitive imaginary, as well as real and imaginary parts for the electric and magnetic field vectors. We take the real part (not the scalar part) of any bivector solution
acting as a non-commutatitive imaginary, as well as real and imaginary parts for the electric and magnetic field vectors. We take the real part (not the scalar part) of any bivector solution  , is a commuting imaginary, commuting with all the multivector elements in the algebra.
, is a commuting imaginary, commuting with all the multivector elements in the algebra. was found to be
was found to be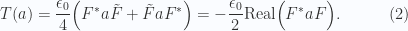

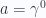 , this four vector divergence takes the form
, this four vector divergence takes the form
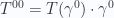 and the Poynting spatial vector
and the Poynting spatial vector 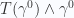 with the current density and electric field product that constitutes the energy portion of the Lorentz force density.
with the current density and electric field product that constitutes the energy portion of the Lorentz force density.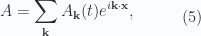
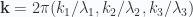 . The Fourier coefficients
. The Fourier coefficients 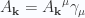 are allowed to be complex valued, as is the resulting four vector
are allowed to be complex valued, as is the resulting four vector  , follows from
, follows from
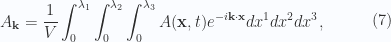
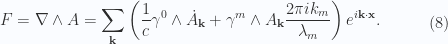
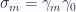 for the spatial basis vectors,
for the spatial basis vectors, 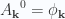 , and
, and  , this is
, this is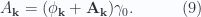




 components of the tensor, which provide a split into energy density
components of the tensor, which provide a split into energy density  , and Poynting vector (momentum density)
, and Poynting vector (momentum density) 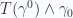 .
.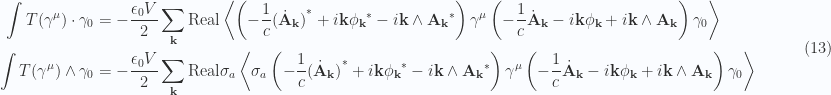

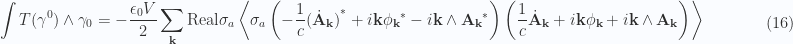
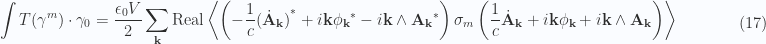


 in the volume
in the volume
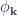 and an observation about when
and an observation about when  equals zero will give us that, but first lets get the mechanical jobs done, and reduce the products for the field momentum.
equals zero will give us that, but first lets get the mechanical jobs done, and reduce the products for the field momentum. only the vector-bivector products can contribute to the scalar product. We have two such products, one of the form
only the vector-bivector products can contribute to the scalar product. We have two such products, one of the form

 in this volume follows by computation of
in this volume follows by computation of
 gives the desired result. Observe that two of these terms cancel, and another two have no real part. Those last are
gives the desired result. Observe that two of these terms cancel, and another two have no real part. Those last are
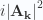 is zero, leaving just
is zero, leaving just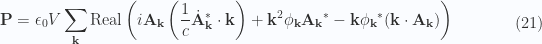
 , quadratic in the vector potential. Is there a mistake above?
, quadratic in the vector potential. Is there a mistake above? , then Maxwell’s equation takes the form
, then Maxwell’s equation takes the form

 such that
such that  . That is
. That is

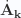 cross term in the Hamiltonian (20) vanishes, as does the
cross term in the Hamiltonian (20) vanishes, as does the 

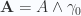 , the lack of an
, the lack of an  component means that this can be inverted as
component means that this can be inverted as
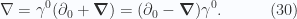
 gauge choice the bivector field
gauge choice the bivector field 
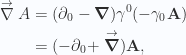


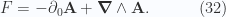


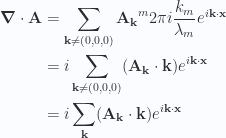
 , there are two ways for
, there are two ways for  . For each
. For each 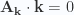 or
or  . The constant
. The constant 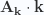 , the second of these Maxwell’s equations is just the vector potential wave equation, since the divergence is zero. That is
, the second of these Maxwell’s equations is just the vector potential wave equation, since the divergence is zero. That is

 , so intuition is either failing me, or my math is failing me, or this contrived periodic field solution leads to trouble.
, so intuition is either failing me, or my math is failing me, or this contrived periodic field solution leads to trouble.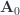 .
. for the assumed Fourier solution should be possible too, but was not attempted. Doing that general calculation with a four dimensional Fourier series is likely tidier than working with scalar and spatial variables as done here.
for the assumed Fourier solution should be possible too, but was not attempted. Doing that general calculation with a four dimensional Fourier series is likely tidier than working with scalar and spatial variables as done here.
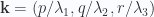 . The Fourier coefficients
. The Fourier coefficients 



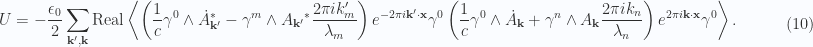



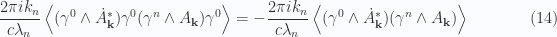
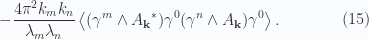
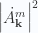 , and the last only products of
, and the last only products of  .
. plus a change of dummy summation indexes in one of the two shows that this sum is of the form
plus a change of dummy summation indexes in one of the two shows that this sum is of the form  . This sum is intrinsically real, so we can neglect one of the two doubling the other, but we will still be required to show that the real part of either is zero.
. This sum is intrinsically real, so we can neglect one of the two doubling the other, but we will still be required to show that the real part of either is zero.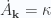 temporarily
temporarily

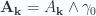 . With such a notation, this contribution to the Hamiltonian is
. With such a notation, this contribution to the Hamiltonian is
 , we can start with just the scalar selection
, we can start with just the scalar selection
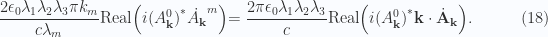
 for short, the grade selection of this term in coordinates is
for short, the grade selection of this term in coordinates is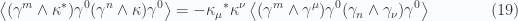
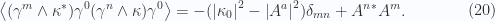
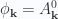 , is then
, is then
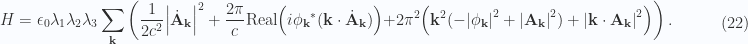
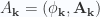 , which is natural since an explicit time and space split was the starting point.
, which is natural since an explicit time and space split was the starting point. 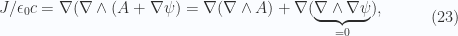




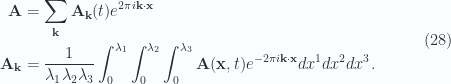






 there must be a requirement for either
there must be a requirement for either 

 for the Faraday bivector, these equations are respectively
for the Faraday bivector, these equations are respectively
 and
and  , the proton charge as
, the proton charge as  , and the electron charge
, and the electron charge  . For the forces we have
. For the forces we have



 and
and  denote the electric fields due to the proton and electron respectively. Ignoring the possibility of self interaction the Lorentz forces on the particles are
denote the electric fields due to the proton and electron respectively. Ignoring the possibility of self interaction the Lorentz forces on the particles are


 . I did just this initially, and was surprised by a mass term of the form
. I did just this initially, and was surprised by a mass term of the form  instead of reduced mass, which cannot be right. The key to avoiding this mistake is the proper considerations of the integration volumes. Since the volumes are different and can in fact be entirely disjoint, subtracting these is not possible. For this reason we have to be especially careful if a differential form of the divergence integrals (9) were to be used, as in
instead of reduced mass, which cannot be right. The key to avoiding this mistake is the proper considerations of the integration volumes. Since the volumes are different and can in fact be entirely disjoint, subtracting these is not possible. For this reason we have to be especially careful if a differential form of the divergence integrals (9) were to be used, as in
 , as measured in the observer frame, and write
, as measured in the observer frame, and write
 is the four vector event specifying the spacetime position of the current, also as measured in the observer frame. Reparameterizating in terms of time should get us back something more familiar looking
is the four vector event specifying the spacetime position of the current, also as measured in the observer frame. Reparameterizating in terms of time should get us back something more familiar looking
 . With the split of the four-volume delta function
. With the split of the four-volume delta function  , where
, where  , we have an explanation for why Jackson had a factor of
, we have an explanation for why Jackson had a factor of 
 , it appears that this works out right. One thing worth noting is that in this time reparameterization I accidentally mixed up
, it appears that this works out right. One thing worth noting is that in this time reparameterization I accidentally mixed up  , the observation event coordinates of
, the observation event coordinates of  , and
, and  , the spacetime trajectory of the particle itself. Despite this, I am saved by the delta function since no contributions to the current can occur on trajectories other than
, the spacetime trajectory of the particle itself. Despite this, I am saved by the delta function since no contributions to the current can occur on trajectories other than 
 if parametrizing the current density with
if parametrizing the current density with 

 is the field due to only the electron charge, whereas
is the field due to only the electron charge, whereas  would be that part of the total field due to the proton charge.
would be that part of the total field due to the proton charge.


 . Putting things together, and writing
. Putting things together, and writing  we have
we have




 , and
, and  where
where 
 and
and  are taken to span the space, but are not required to be orthogonal. The notation is consistent with the Dirac reciprocal basis, and there will not be anything in this treatment that prohibits the Minkowski metric signature required for such a relativistic space.
are taken to span the space, but are not required to be orthogonal. The notation is consistent with the Dirac reciprocal basis, and there will not be anything in this treatment that prohibits the Minkowski metric signature required for such a relativistic space.


 in terms of coordinates we have
in terms of coordinates we have

 . For the vector x we can form a pseudoscalar for the subspace spanned by this parametrization by wedging the displacements in each of the directions defined by variation of the parameters. For
. For the vector x we can form a pseudoscalar for the subspace spanned by this parametrization by wedging the displacements in each of the directions defined by variation of the parameters. For ![m \in [1,k]](https://s0.wp.com/latex.php?latex=m+%5Cin+%5B1%2Ck%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002) let
let


 and can specify our volume element in terms of the Jacobian determinant.
and can specify our volume element in terms of the Jacobian determinant.

 we have for the dot and wedge product respectively
we have for the dot and wedge product respectively





 ) it is straightforward to show that (2.11) also holds.
) it is straightforward to show that (2.11) also holds.
 will serve to illustrate the pattern, and the generalization (or degeneralization to lower grades) will be clear. We have
will serve to illustrate the pattern, and the generalization (or degeneralization to lower grades) will be clear. We have
 with
with  can now be made explicit without as much mess.
can now be made explicit without as much mess.

 example is reduced to
example is reduced to
 . This expansion for the
. This expansion for the 
 . This with the definitions 2.7, and 2.8 is really Stokes theorem in its full glory.
. This with the definitions 2.7, and 2.8 is really Stokes theorem in its full glory.![dx_i = da_i {\partial {x}}/{\partial {a_i}}, i \in [1,k]](https://s0.wp.com/latex.php?latex=dx_i+%3D+da_i+%7B%5Cpartial+%7Bx%7D%7D%2F%7B%5Cpartial+%7Ba_i%7D%7D%2C+i+%5Cin+%5B1%2Ck%5D&bg=fafcff&fg=2a2a2a&s=0&c=20201002) are nothing more abstract that plain old vector differential elements. In the formalism of differential forms, this would be vectors, and
are nothing more abstract that plain old vector differential elements. In the formalism of differential forms, this would be vectors, and  would be a
would be a  parameters. That is
parameters. That is
 ).
).


 . Then we have
. Then we have

 ,
,  , and
, and  . We then have
. We then have


 , and the four volume element
, and the four volume element  . This gives
. This gives
 , for
, for

 ) from the dual Stokes equation the perhaps less obvious result
) from the dual Stokes equation the perhaps less obvious result ,
,  ,
, 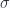 generate a set of differential vector displacements spanning the three dimensional subspace
generate a set of differential vector displacements spanning the three dimensional subspace


 ,
,  , and
, and  . For a bivector, the flux through the surface is therefore
. For a bivector, the flux through the surface is therefore

 . Expanding the latter is probably easier than regrouping the mess, and doing so we have
. Expanding the latter is probably easier than regrouping the mess, and doing so we have


 ,
,  interchange in the first term inverts the sign, we have an exact match with (5), thus fixing the sign for the bivector form of Stokes theorem for the orientation picked in this diagram
interchange in the first term inverts the sign, we have an exact match with (5), thus fixing the sign for the bivector form of Stokes theorem for the orientation picked in this diagram
