Over the years the kids and I have over aggressively used the banister as we charge up and down the stairs. It’s been loose for a while but it didn’t really occur to me that it was fixable. Now, we’ve just sold the house, and the buyer’s identified this as a defect that they wanted fixed as part of the closing conditions.
It turns out that it is fixable. The very knowledgeable guy who works in our neighborhood home depot in doors and windows department told me how to do this. Basically, take it all apart, and then put it all back together.
This requires:
- First taking out the underside screws that hold the wood rail onto the metal underside.
- Now you can unscrew the metal rail from the spindles.
- Pull the loose spindles
- Clean the old glue off the floor and the spindles.
- Glue them back in.
- Screw the metal rail back onto the top of the spindles.
- Screw the wood rail back on.
This is a lot easier to see in pictures. The end result of the wild kids and dads in the house over the years resulted in the spindles being pulled from the floor like so:
")
Are you wondering why there is tape on the floor? I put that there like registration marks in printing. That way the spindles end up aligned the same way they were originally. I did these tape markers all the way up and down the stairs, and it probably mattered most right down at the base (where the builder was a cheapskate and didn’t put a newel post that probably would have made the banister properly stable).
")
I also marked each post with a number so that the sequence of the posts was retained. You can see that in this picture, where I’d taken the wood railing off:
")
Once the metal was removed, you can really see how free the spindles were in their holes:
")
With very little effort I could rotate these in place once the screw was removed. Next step is removing the metal rail completely, and setting it aside with the wood rail
")
Now that the rails are both off, the posts can be pulled, and it’s time to clean up the old glue residue. I was actually surprised how little glue the original installer appeared to use, and cleaning it off the floor wasn’t too hard. I used a chisel to lightly scrap it off without damaging the surrounding stair finish (since my initial attempt using sandpaper looked like it was going to wreck the finish)
")
I ended up glad that I’d marked the posts numerically, since it would have been easy to mix them up, even with orderly placement. When you look at a finished staircase banister, you don’t even notice the fact that each one is a different length
")
The glue also has to be cleaned off of the spindle bases, once they are pulled out. You can see how it wasn’t wiped off well by the original installer
")
A little chiselling and sandpapering handles that nicely
")
Again I was really surprised how little glue the original installer used. I hardly had to take any off of all the little knobs on the base of each spindle.
I ended up pulling out all but two of the spindles, since two at the base were in firmly enough that I didn’t think I needed to touch them.
")
That may have been a mistake, since that part of the banister is still the loosest part of the railing. I think that what really ought to have been on the staircase is a newel post, and not the wimpy set of curved spindles that were used. I wasn’t about to try to retrofit one in though, since that probably would have meant completely redoing the staircase. With everything removed, it was time for some carpenters glue on the spindle begs and bottom, put em back in the holes, align them, and wipe up the excess glue after squishing them down into their seats nicely. That looked like it did near the beginning:
")
Next was putting the wood back on. I actually had a fair amount of trouble with this part, and it didn’t align properly anymore. I loosened up the big screw at the top of the stairs that held the metal rail to the wall, and was able to get it back on in the end, but I had to kind of lever it on. The end result is something that doesn’t look any different than the original from a distance
")
If you look closely now, the gaps that used to be at the base of each post are now gone, and the wall near the top is a bit mucked up (needs a small touch up plastering and paint touch up that I’m not going to bother with). But it is a whole lot stronger feeling, and the new owner should be satisfied with the result. I’m assuming that they only wanted that one repaired. The top part of the staircase banister now feels looser in comparison, but I didn’t used to notice that one, and don’t feel like tackling that project unless forced. I’d like that to be a SOP for the new owner.








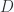


































 to the center of the hoop, which I believe required.
to the center of the hoop, which I believe required. , and
, and  , we have
, we have


 . Let’s switch our dynamical variables to ones that express the deviation from the initial point
. Let’s switch our dynamical variables to ones that express the deviation from the initial point  , and
, and  , with
, with  , and
, and  . Our system then takes the form
. Our system then takes the form
 . So, to first order, our system has the approximation
. So, to first order, our system has the approximation



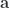 , and
, and 
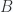 should allow the exponential and inverse to be calculated with less work. That inverse is readily verified to be
should allow the exponential and inverse to be calculated with less work. That inverse is readily verified to be




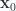 in phase space. Can these be related to each other?
in phase space. Can these be related to each other?")
")
")
")
")
")
")
")
")
")
")
")
