Some previous posts have discussed implementations of mutual exclusion code for a few hardware platforms. PowerPC is an interesting case due to the possibility of unordered memory accesses. I wanted to get a rough idea what the relative costs of an atomic sequence of instructions, plus the required memory barriers that are required to implement a mutex. This is surprisingly tricky to measure, and I thought I’d start with something that would give me the absolute minimum cost ; how much time does it take to repeatedly do a pair of atomic operations in a single threaded, completely uncontended fashion, with and without memory barriers. A fragment of code that illustrates this is:
inline long atomicCompareAndIncrement( volatile long * a, long c, long v )
{
long old = c ;
__compare_and_swaplp( a, &old, c + v ) ;
return old ;
}
// ...
else if ( doIsync && doLwsync )
{
for ( long i = 0 ; i < n ; i++ )
{
v = atomicCompareAndIncrement( &a, i, 1 ) ;
__isync( ) ;
__lwsync( ) ;
v = atomicCompareAndIncrement( &a, i, 1 ) ;
}
}
The compiler, perhaps knowing that its builtins have side effects, and unlike me, likely also not knowing that there are no other threads, does not optimize away this loop (no other threads it could probably figure out since I have only a single main function).
I wanted to have a comparison of this sort of loop with straight load and store pairs that have the same effect, and then just a loop of the lowest cost instructions, arithmetic ones. These last are tricky to get because the compiler optimizes away the loop. For example, the following code is almost completely optimized away:
long plainOldIncrementFunction( long v1, long v2 )
{
return v1 + v2 ;
}
// ...
else if ( impossibleOption )
{
/* guessing this will be completely optimized away ... yup. */
for ( long i = 0 ; i < n ; i++ )
{
v = plainOldIncrementFunction( v, 1 ) ;
v = plainOldIncrementFunction( v, 1 ) ;
}
}
Declaring the function non-inline doesn’t help. The compiler does generate a copy of this function body, but it is never called in main(), and the whole loop is missing in action when you look at the assembly listing.
I used a trick that I’d previously used, making use of xlC’s inline assembly construct, the mc_func (machine code function). In case you haven’t seen it before, this is a brute force way of getting specific desired instructions into the code, as if they were function calls. Here’s the ones that I created for this
/*
long loadAndAddAndStore( long * a, long i )
{
long v = *a ;
*a = v + i ;
return v ;
}
*/
extern "C" long loadAndAddAndStore( volatile long * a, long v ) ;
#pragma mc_func loadAndAddAndStore { \
"e8030000" /* ld r0,0(r3) */ \
"7c802214" /* add r4,r0,r4 */ \
"f8830000" /* std r4,0(r3) */ \
"60030000" /* ori r3,r0,0x0000 */ \
}
#pragma reg_killed_by loadAndAddAndStore gr0,gr3,gr4
/*
long plainOldIncrement( long v1, long v2 )
{
return v1 + v2 ;
}
*/
extern "C" long plainOldIncrement( long v1, long v2 ) ;
#pragma mc_func plainOldIncrement { \
"7c632214" /* add r3,r3,r4 */ \
}
#pragma reg_killed_by plainOldIncrement gr3
There are three parts to each mc_func. One is the equivalent prototype, a fake function call interface that specifies the inputs and outputs of the function. One has to know the PowerPC calling convention to use this. Specifically that input parameters (up to eight of them) come in registers gr3,gr4,…, and output is in gr3. The next part of an mc_func is the set of opcodes for the machine code that you desire in the code. Note that the comments included in this sequence (like: add r3,r3,r4) are NOT part of the mc_func. I just included those for my own benifit. As far as the compiler is concerned, the mc_func provides only a set of opcodes, so something like:
#pragma mc_func loadAndAddAndStore { "e8030000" "7c802214" "f8830000" "60030000" }
is no different from my “readable” version. Isn’t that the ultimate in an unfriendly user interface? It is a user interface that is probably deliberately hard to use as a means to discourage the evil developer from even trying. Fortunately, there are sneaky ways you can do this. I dropped the C code versions of the interfaces I wanted into a separate module and compiled that with xlC -S. I was then able to run ‘as -a64 -l’ on the generated .s file, to produce a listing with the desired opcodes and cut and paste that into the mc_func blocks I desired.
I was able to use this bit of hackery to construct the mc_func’s that were desired. Since the compiler doesn’t know what’s in those, and only knows that they externally effect the list of registers in the clobber constraints, it doesn’t optimize that away.
I was able to get some basic measurements this way. This answered the question of how much more expensive uncontended atomics are than plain old memory operations, and what the minimal additional cost the isync and lwsync instructions introduce. The isync and lwsync’s didn’t appear to add much cost in this uncontended scenerio, and that’s perhaps not too surpising since I didn’t put in any other memory operations that have to be ordered by those barriers.
The measurements I made are fairly artificial and unsatisfactory, mostly because of no other cache access, especially no remote cache access. That can get really expensive, and remote caches can be behave in a very numa like fashion. The cost of going to the L2 cache on the same board (CAC is what I think AIX calls these) is much less than going to one of the remote caches. How could these sort of costs be measured systematically? That I don’t know. I’d bet that when multiple cachelines enter the picture, especially when contended, that is when you also start to see the costs of the memory barrier instructions. It is interesting to see how well those costs can be optimized away in the uncontended scenerio!

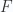

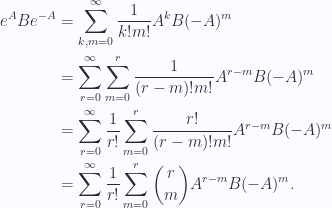


![\begin{aligned}\binom{1}{0} A B + \binom{1}{1} B (-A) &= \left[{A},{B}\right]\end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Cbinom%7B1%7D%7B0%7D+A+B+%2B+%5Cbinom%7B1%7D%7B1%7D+B+%28-A%29+%26%3D+%5Cleft%5B%7BA%7D%2C%7BB%7D%5Cright%5D%5Cend%7Baligned%7D+&bg=fafcff&fg=2a2a2a&s=0&c=20201002)


![\begin{aligned}\left[{A},{\left[{A},{B}\right]}\right]&= A(A B - B A) -(A B - B A)A \\ &= A^2 B - A B A - A B A + B A^2 \\ &= A^2 B - 2 A B A + B A^2 \\ \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D%5Cleft%5B%7BA%7D%2C%7B%5Cleft%5B%7BA%7D%2C%7BB%7D%5Cright%5D%7D%5Cright%5D%26%3D+A%28A+B+-+B+A%29+-%28A+B+-+B+A%29A+%5C%5C+%26%3D+A%5E2+B+-+A+B+A+-+A+B+A+%2B+B+A%5E2+%5C%5C+%26%3D+A%5E2+B+-+2+A+B+A+%2B+B+A%5E2+%5C%5C+%5Cend%7Baligned%7D+&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
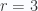
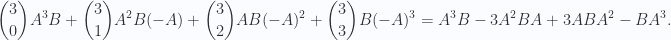
![\begin{aligned} [A, [A, [A, B] ] ] &= A^3 B - 2 A^2 B A + A B A^2 -(A^2 B A - 2 A B A^2 + B A^3) \\ &= A^3 B - 3 A^2 B A + 3 A B A^2 -B A^3 \\ \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5BA%2C+%5BA%2C+%5BA%2C+B%5D+%5D+%5D+%26%3D+A%5E3+B+-+2+A%5E2+B+A+%2B+A+B+A%5E2+-%28A%5E2+B+A+-+2+A+B+A%5E2+%2B+B+A%5E3%29+%5C%5C+%26%3D+A%5E3+B+-+3+A%5E2+B+A+%2B+3+A+B+A%5E2+-B+A%5E3+%5C%5C+%5Cend%7Baligned%7D+&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
![\begin{aligned}C_r(A,B) &\equiv \underbrace{[A, [A, \cdots, [A,}_{r \text{times}} B]] \cdots ] = \sum_{m=0}^r \binom{r}{m} A^{r-m} B (-A)^m,\end{aligned} \hspace{\stretch{1}}(2.2)](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7DC_r%28A%2CB%29+%26%5Cequiv+%5Cunderbrace%7B%5BA%2C+%5BA%2C+%5Ccdots%2C+%5BA%2C%7D_%7Br+%5Ctext%7Btimes%7D%7D+B%5D%5D+%5Ccdots+%5D+%3D+%5Csum_%7Bm%3D0%7D%5Er+%5Cbinom%7Br%7D%7Bm%7D+A%5E%7Br-m%7D+B+%28-A%29%5Em%2C%5Cend%7Baligned%7D+%5Chspace%7B%5Cstretch%7B1%7D%7D%282.2%29&bg=fafcff&fg=2a2a2a&s=0&c=20201002)

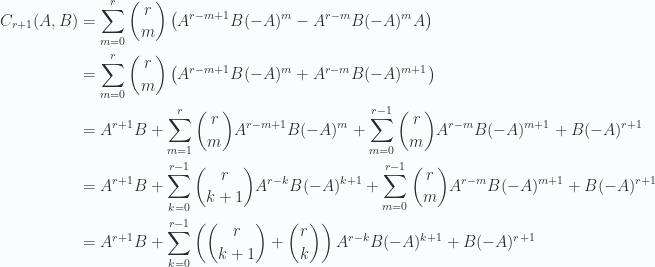









![\begin{aligned}e^A B e^{-A}&=B + \frac{1}{{1!}} \left[{A},{B}\right]+ \frac{1}{{2!}} \left[{A},{\left[{A},{B}\right]}\right]+ \cdots\end{aligned} \hspace{\stretch{1}}(2.4)](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7De%5EA+B+e%5E%7B-A%7D%26%3DB+%2B+%5Cfrac%7B1%7D%7B%7B1%21%7D%7D+%5Cleft%5B%7BA%7D%2C%7BB%7D%5Cright%5D%2B+%5Cfrac%7B1%7D%7B%7B2%21%7D%7D+%5Cleft%5B%7BA%7D%2C%7B%5Cleft%5B%7BA%7D%2C%7BB%7D%5Cright%5D%7D%5Cright%5D%2B+%5Ccdots%5Cend%7Baligned%7D+%5Chspace%7B%5Cstretch%7B1%7D%7D%282.4%29&bg=fafcff&fg=2a2a2a&s=0&c=20201002)
